I’ve been feeling slightly guilty over the last few days because I’ve been thinking privately about the problem of improving the Roth bounds. However, the kinds of things I was thinking about felt somehow easier to do on my own, and my plan was always to go public if I had any idea that was a recognisable advance on the problem.
I’m sorry to say that the converse is false: I am going public, but as far as I know I haven’t made any sort of advance. Nevertheless, my musings have thrown up some questions that other people might like to comment on or think about.
Two more quick remarks before I get on to any mathematics. The first is that I still think it is important to have as complete a record of our thought processes as is reasonable. So I typed mine into a file as I was having them, and the file is available here to anyone who might be interested. The rest of this post will be a sort of digest of the contents of that file. The second remark is that I am writing this as a post rather than a comment because it feels to me as though it is the beginning of a strand of discussion rather than the continuation of one, though it grows out of some of the comments made on the last post. Note that since we are operating on the Polymath blog, anybody else is free to write a post too (if you are likely to be one of the main contributors, haven’t got moderator status and want it, get in touch and I can organize it).
The starting point for this line of thought is that the main difficulty we face seems to be that Bourgain’s Bohr-sets approach to Roth is in a sense the obvious translation of Meshulam’s argument, but because we have to make a width sacrifice at each iteration it gives a 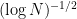

After thinking about this question in somewhat vague terms for quite a while, I have now reached a more precise formulation of it. To begin with, I want to avoid the technical issue of regularity, which can be thought of as arising from the fact that a lattice is a discrete set and therefore behaves a little strangely at small distance scales. We sort of know that that creates only technical difficulties, so if we want to get a feel for what is true, then it is convenient to think of a Bohr set as being a symmetric convex body in 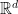
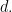
The question I want to consider is this. Let 

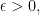




Actually, what I really want is (I think — I haven’t checked this formulation as carefully as I should have) a trigonometric function 

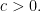
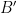



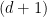
Reasons to be pessimistic.
Let me try to put as strongly as I can the argument that there is no hope of getting a density increase without a width sacrifice.
To begin with, think what a typical 3AP looks like. For the purposes of this argument, I’ll take 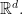
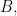
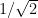

What this simple example shows is that if we want to obtain a density increase, it will not be enough to use the fact that
Pushing this example slightly further, even the set 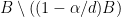

But if we restrict attention to 3APs with small common difference, can we hope to find a “global” density increase, as opposed to the “local” density increase one would obtain by passing to a smaller-width Bohr set? Consider what happens, for instance, if one has a subset of 

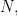
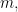
Reasons to be less pessimistic.
We seem to be in a difficult situation: one example appears to force us to consider small common differences (though in fact Bourgain doesn’t, because instead of restricting the difference of the 3AP he restricts its central element to lie in a small Bohr set), while another example appears to suggest that from the fact that there are no 3APs with small common difference one cannot conclude that there is global correlation with a trigonometric function.
However, there is a mismatch between the two examples, and at the moment I cannot rule out that the mismatch is pointing to something fundamental. The mismatch is this: the first example (where we take a sphere and remove the heart) works because we are in a high dimension, whereas the second works because we are in a low dimension.
Let me explain what I mean. The first example relied strongly on measure concentration, so it is clear that it needed us to be in a high dimension. As for the second, it relied on our being able to say that if you take two points 



What interests me about this is that the smallness you need in order to deal with the first example seems to be very closely related to the smallness you need in order to make the second example work. In the first case, you need to drop down to a distance scale 

Who is correct, the optimist or the pessimist?
One problem with the optimist’s argument above is that it is qualitative. I argued qualitatively that the very high-dimensionality that makes the first example work stops the second example working. But it is conceivable that one might manage to turn that into a rigorous argument that showed that one could get away with dropping the width by a factor of 2 instead of something like 

But if the optimist is correct, then a natural question arises: how would one go about turning that qualitative argument into a rigorous and quantitative proof that not having small APs leads to a global correlation with a trigonometric function? One’s first instinct is to think that it would be necessary to classify Bohr sets according to their “true” dimension, or something like that — which would be difficult, as the structure of a Bohr set depends in subtle ways on the various linear relations between the characters that define it. If we take it as read that any such classification would be bound to lose constants in a way that would destroy any hope of the kind of exact result we would need, what does that leave?
The main thing we have to decide is our “distance scale”. That is, we are given a Bohr set 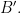

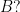
The only possible answer I can think of is to define 
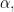
It looks more and more as though it would be necessary to consider not just Bohr sets in isolation, but Bohr sets as members of ensembles. Fortunately, thanks to work of Ben Green and Tom Sanders, we have the idea of a Bourgain system to draw on there.
Let me give one further thought that makes me dare to hope a little bit. It seems that quite a lot of our problems are caused by the fact that high-dimensional Bohr sets have boundaries, and measure concentrated on those boundaries. But if we pass to a “shell” (by which I mean a set that is near the boundary) then it does not have a boundary. (By the way, any argument that seems to be making us consider a spherical shell is sort of interesting, given that it raises the hope of ultimately connecting with the Behrend lower bound.) In order to think about what happens when we are in a high-dimensional set with no boundary, let us now suppose we are in the group 
What happens, though, if we restrict the common difference to be small in some sense? I’m not sure, but let me at least do the Fourier calculation. It is not hard to check that 
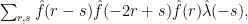


In low dimensions I would normally deal with such a sum by taking 
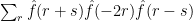

I’m going to leave this here, but let me quickly make a remark about the pdf file that I linked to at the beginning of this post. It is not meant to be anything like a polished document, which means it shouldn’t even necessarily be assumed to be correct. In fact, at the top of page 11 I made quite an important mistake: the expression I wrote down is not the probability I said it was; to get that probability one needs to replace the third 

[…] me update this. There is a new post. Also see these […]
Pingback by Polymath6 « Euclidean Ramsey Theory — February 13, 2011 @ 9:42 pm |
Here is a toy problem that may possibly capture the kind of thing I am asking. I’ll work in the group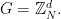 Let
Let  be the Bohr set
be the Bohr set ![[-N/8,N/8]^d](https://s0.wp.com/latex.php?latex=%5B-N%2F8%2CN%2F8%5D%5Ed&bg=ffffff&fg=000000&s=0&c=20201002) (there is nothing special about the number 8 here), let
(there is nothing special about the number 8 here), let  be the characteristic measure of
be the characteristic measure of  and let
and let 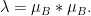 (There is not even anything particularly special about
(There is not even anything particularly special about  : I want something Bohr-set-like, but thought it might be convenient if it had more quickly decaying Fourier coefficients.) Suppose that
: I want something Bohr-set-like, but thought it might be convenient if it had more quickly decaying Fourier coefficients.) Suppose that 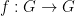 is a bounded function (that is,
is a bounded function (that is,  ) such that on average the product of
) such that on average the product of  with a translate of
with a translate of  correlates with a trigonometric function. Does it follow that
correlates with a trigonometric function. Does it follow that  itself correlates with a trigonometric function?
itself correlates with a trigonometric function?
I’m not quite sure how to make that precise when is an arbitrary function, but let us suppose that
is an arbitrary function, but let us suppose that  for a subset
for a subset  of density
of density  Then I can give a quantitative version of the question as follows. For each
Then I can give a quantitative version of the question as follows. For each 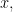 define the trigonometric bias
define the trigonometric bias  of
of  with respect to the translate
with respect to the translate 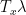 (where
(where  to be the maximum value of
to be the maximum value of  where
where  is a character on
is a character on  Suppose now that the average trigonometric bias is at least
Suppose now that the average trigonometric bias is at least  Does it follow that there exists a non-trivial character
Does it follow that there exists a non-trivial character  such that
such that  (at least if
(at least if 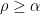 )?
)?
A simple argument gives a positive answer but with depending exponentially on the dimension
depending exponentially on the dimension 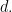 The point of the question is to try to remove the dependence on
The point of the question is to try to remove the dependence on 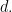 And the reason it might conceivably be possible to do something like that is that obvious constructions such as partitioning
And the reason it might conceivably be possible to do something like that is that obvious constructions such as partitioning  into
into  boxes of side length
boxes of side length  and making
and making  correlate with a random trigonometric function in each box simply don’t work: a typical translate of
correlate with a random trigonometric function in each box simply don’t work: a typical translate of  intersects all the boxes, so we don’t get the local correlation.
intersects all the boxes, so we don’t get the local correlation.
I’m not claiming that a good result along these lines solves all our problems, but I do think that it would suggest strongly that this approach has possibilities.
Comment by gowers — February 14, 2011 @ 10:06 am |
Let me suggest an approach to proving what I want. I would like to show that if is a bounded function defined on
is a bounded function defined on  (that is, it takes values of modulus at most 1), then with high probability if you choose a random
(that is, it takes values of modulus at most 1), then with high probability if you choose a random  the inner product
the inner product  is close to
is close to  I haven’t quite found the calculation that shows this, but it feels as though the first expectation may be enough like taking an independent random sample of values of
I haven’t quite found the calculation that shows this, but it feels as though the first expectation may be enough like taking an independent random sample of values of  to make the result true. If so, it might be the beginning of the local-to-global principle (I don’t mean quite what most people mean when they use that phrase) that I am looking for.
to make the result true. If so, it might be the beginning of the local-to-global principle (I don’t mean quite what most people mean when they use that phrase) that I am looking for.
Comment by gowers — February 14, 2011 @ 12:03 pm |
It might have been clearer if I had said something like “ -wise independent” rather than “independent” above.
-wise independent” rather than “independent” above.
Comment by gowers — February 14, 2011 @ 12:05 pm |
Sorry — it was a stupid question in that it is trivially false. The counterexample is to take to be a non-trivial trigonometric function that correlates with
to be a non-trivial trigonometric function that correlates with  What I think I want is to show that this sort of example is essentially the only kind. No time now, but I’ll have to think about a better formulation of the question.
What I think I want is to show that this sort of example is essentially the only kind. No time now, but I’ll have to think about a better formulation of the question.
Comment by gowers — February 14, 2011 @ 12:26 pm |
I think the kind of statement I’m going to want is that the only counterexamples are fairly “continuous” functions, which will necessarily have large Fourier coefficients (and not just any old Fourier coefficients either).
Comment by gowers — February 14, 2011 @ 3:28 pm |
I have a question as an “observer”. Is it clear why the epsilon gained by Michael and Netz necessary small or perhaps we can hope also for a large epsilon? (If so maybe we can start with the 2/3 exponent, anyway, or even the loglogn Roth). A related question is: Is the argument of Michael and Netz allows adding an epsilon to Bourgain 2/3? (I am aware better results are known but still this seems interesting.)
Comment by Gil Kalai — February 14, 2011 @ 6:55 pm |
Tom Sanders has also asked this question. He is pretty sure there wouldn’t be much problem (apart from a certain necessary technical slog) in improving any of the 1/2, 2/3 or 3/4 bound by the Bateman-Katz epsilon. It seems that that epsilon is necessarily very small if you stick closely to their argument. Whether one can be more precise and say that there is a certain barrier beyond which one cannot go without a new idea I do not know.
Comment by gowers — February 14, 2011 @ 7:54 pm |
Gil–
Someone asked similar questions via email earlier. Here was my comment then:
————
About the size of epsilon in the BK paper: Section 6 in particular requires epsilon to be rather microscopic. This is the structural theorem for sets with some additive energy but no additive smoothing. As epsilon grows, the sharpness of the nonsmoothing hypothesis goes away; and over the course of the proof of this theorem, the nonsmoothing parameter gets magnified a number of times, leaving a vacuous theorem unless the nonsmoothing parameter (and consequently epsilon) is very small.
The reason the nonsmoothing hypothesis can disappear as epsilon grows is that the size of the spectrum can increase substantially (– specifically it could be as large as (density)^{-3}). Then the random selection argument (–at least in its current form — which chooses sets of size about N) becomes a less effective way of estimating the number of m-tuples in the spectrum.
————-
I have no idea whether you have looked at our paper, so I’ll just ramble a bit more in case it’s helpful. [BK] includes a theorem for sets that are not “additively smoothing”. A set S is said to be additively smoothing if its difference set has more structure than itself. One way to detect this is by comparing the L^p norms of the fourier transform of the set. (In fact this is how we define it precisely.) (For p even) We know that the L^p norm is the number of p-tuples in the set S. By Holder’s inequality, an estimate on the number of (say) 4-tuples gives us a free estimate on the number of (say) 8-tuples. If there are only this many 8-tuples, we say the set is NOT smoothing. If there are many more, we say the set IS smoothing. For example, consider a set of size M randomly distributed in a subspace of size M^{1+c} for some 0<c<1. This is the additively smoothing example because M-M is all of the subspace, which has perfect additive structure. An non-smoothing example is something like a bunch of (smaller) subspaces with no relation to each other. Here the set of (popular) differences is just the set we started with, which has (trivially) no additional additive structure.
Epsilon being small allows us to conclude that the spectrum is nonsmoothing. The paper includes a structural theorem for nonsmoothing sets. Large epsilon means smoothing is a possibility. If there were an equally strong structural theorem for sets with additive smoothing, there might be some hope; but such a theorem would not be a trivial extension of our result.
Michael
Comment by Michael Bateman — February 14, 2011 @ 7:58 pm |
(My apologies in advance for the poor formatting; I realized my faux pas with not enough time to fix it before tomorrow.)
Here are some half-baked thoughts about possibly increasing the size of epsilon.
My knowledge of covering lemmas and related technology is a bit thin. We already have a structural theorem for sets S such that S is not smoothing. Could we possibly use this to prove a structural theorem for sets S such that, say, 2S is not smoothing? how about 4S? etc. This seems like an interesting question because of the following sketch.
As mentioned above, when epsilon grows the spectrum may become additively smoothing, which is a problem (at least for the existing technology). What I notice, however, is that even when epsilon is large, we may still conclude (something like?) one of the iterated difference sets is not additively smoothing. By using the random selection argument as in [BK], we can conclude that the number of 2m-tuples is less than
N^{4m + mO(epsilon)} .
Since the number of 4-tuples is known to be
N^{7-O(epsilon)}
in this case, it is possible for the number of 8-tuples to be as large as
N^{15+ O(epsilon)}
without reaching a contradiction. As epsilon grows, this ruins the non-smoothing of the spectrum.
Write E_{2m} to denote the number of 2m-tuples in the spectrum S. Suppose we have a smoothing-like condition at every “step”. More precisely, suppose E_{2m} is larger than the trivial Holder bound over E_m plus an additional factor of E_m ^{beta} for some small number beta. If this is true for m=3,4,5,…, M, where M depends on beta and epsilon, then we contradict the estimate E_{2M} < N^{4M + MO(epsilon)} mentioned above that we obtained from the random selection argument. Hence we must not have this additional beta smoothing for every m. If we write S for the spectrum, this seems to say something an awful lot like "2mS is additively non-smoothing".
Comment by Michael Bateman — February 15, 2011 @ 1:13 am |
Dear Tim,
here are just some vague thoughts I had after reading your post and .pdf-file, which I’d like to write down here – basically in order to see whether I understood those things properly. Yet before getting started I should perhaps say that although this comment is unfortunately somewhat long, it doesn’t give any new ideas, it’s just sort of a reformulation of some things you’ve already said.
It seems that one may look at any argument proving a version of Roth’s theorem that involves density increments as a method (in a not too algorithmic sense of this word) to actually find a 3AP in a set satisfying the requested density bound by making successively better guesses as to where such an 3AP could be. Thus in the original argument, we start with a set living in
living in  of size
of size  , compute certain Fourier coefficients, and then guess that (one of) the 3AP(s) of
, compute certain Fourier coefficients, and then guess that (one of) the 3AP(s) of  can actually be found in a certain subprogression, then we do the very same computations there, make a further guess, and so forth until our guesses become precise enough to actually locate 3AP inside
can actually be found in a certain subprogression, then we do the very same computations there, make a further guess, and so forth until our guesses become precise enough to actually locate 3AP inside  , at which point we are done. The verious improvements over Roth’s orinal result can then be regarded as providing descriptions of much better strategies for making these guesses.
, at which point we are done. The verious improvements over Roth’s orinal result can then be regarded as providing descriptions of much better strategies for making these guesses.
So far our guesses can also be thought of as assigning zeros and ones to the elements of in each step, where those elements among which we still look for a 3AP get assigned ones, while the other ones receive zeros. If we formulate the strategy behind the proof like this, the idea of assigning reals from the interval
in each step, where those elements among which we still look for a 3AP get assigned ones, while the other ones receive zeros. If we formulate the strategy behind the proof like this, the idea of assigning reals from the interval ![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=ffffff&fg=000000&s=0&c=20201002) instead of just zeros and ones doesn’t appear unnatural: So in each stage we could construct a function
instead of just zeros and ones doesn’t appear unnatural: So in each stage we could construct a function  from
from  to
to ![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=ffffff&fg=000000&s=0&c=20201002) , and an equation like
, and an equation like  intuitively means “For the time being I won’t consider 3AP(s) through
intuitively means “For the time being I won’t consider 3AP(s) through  any further”, while
any further”, while  could mean “At the moment it’s not particularly likely, but still possible that I will end up producing a 3AP through
could mean “At the moment it’s not particularly likely, but still possible that I will end up producing a 3AP through  “, an equation like “f(a)=2f(a’)” roughly means “Currently it seems twice as likely that our eventual 3AP will pass through
“, an equation like “f(a)=2f(a’)” roughly means “Currently it seems twice as likely that our eventual 3AP will pass through  than that it passes through
than that it passes through 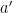 “, and so on.
“, and so on.
Now for Roth’s original argument it is definitely essential for technical reasons to just work with -valued functions (as one “changes
-valued functions (as one “changes  ” throughout the proof), even though this appears to lead to some more or less arbitrary but at the same time rather immaterial choices concerning the boundaries of the subprogressions to which one passes when iterating. But already for Bourgains argument (my understanding of which on a conceptual level is surely by far more limited than yours), it doesn’t seem to be clear why one has to do so, and if I happen to understand what you suggest to some extent correctly, then you propose to work with a guessing function
” throughout the proof), even though this appears to lead to some more or less arbitrary but at the same time rather immaterial choices concerning the boundaries of the subprogressions to which one passes when iterating. But already for Bourgains argument (my understanding of which on a conceptual level is surely by far more limited than yours), it doesn’t seem to be clear why one has to do so, and if I happen to understand what you suggest to some extent correctly, then you propose to work with a guessing function  whose values at the center of the Bohr set under consideration is much greater then the value of
whose values at the center of the Bohr set under consideration is much greater then the value of  near the boundary. (Instead of taking
near the boundary. (Instead of taking  to be the characteristic function of the Bohr set involved.)
to be the characteristic function of the Bohr set involved.)
At this point, it seems that maybe one can even dispose of working with Bohr sets on a strictly technical level and instead merely “think of them in the back of our head”, transforming at each step of the iteration the definition of the Bohr set of which we “really think” into an appropriate definition of a certain guessing function (which probably then has to somehow “codify” certain pieces of “regularity information” on that Bohr set, etc.)
Comment by Christian — February 14, 2011 @ 8:35 pm |
What I meant with the last paragraph was just this: It is not even clear why one should assign strict zeros instead of just very small numbers to the points outside the Bohr set under consideration, which conceivably might then turn out to be “technically easier”, though it should’t be essential either.
Comment by Christian — February 14, 2011 @ 9:00 pm |
Maybe, given the amount of discussion, this is a good place to concentrate both polymath6ing and openly discussing both Roth and the cupset problem, both lower bounds and upper bounds.
About 10-12 years ago Roy Mshulam and I thought quite extensively (without success) about trying to improve the Fourier argument even slightly. (We had more avant-garde ideas about the problem more recently that I discussed over my blog.) Anyway, we had a certain proposed conjecture (whose strength depends on various parameters) about general functions and I wonder how this conjecture survive the killer examples described by Tim and if the argument by Michael and Nets gives also it.
So lets consider and for a function
and for a function  and
and  and
and  we denote by
we denote by  the maximum over affine k-dimensional flats
the maximum over affine k-dimensional flats  of
of  .
.
Now the conjecture is that for some constant and some negotiable
and some negotiable  every set
every set  of size
of size 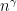 the following holds:
the following holds:
(**)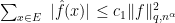
It turns out that if (**) holds with , and
, and 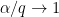 then the
then the 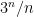 upper bound for cupsets can be improved to
upper bound for cupsets can be improved to  for every
for every  .
.
In fact, if you fix between 2 and 3 you can have
between 2 and 3 you can have  So you can adjust the above parameters in the conjecture to imply stronger and weaker forms of the cap conjecture. We could say something for very very specific E’s but not for anything near the general case. We can adjust (**) with
So you can adjust the above parameters in the conjecture to imply stronger and weaker forms of the cap conjecture. We could say something for very very specific E’s but not for anything near the general case. We can adjust (**) with 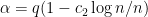 and
and  to have (**) implies
to have (**) implies  upperbounds so maybe some killer examples or some other examples already kill this. Also we can adjust the parameters to make
upperbounds so maybe some killer examples or some other examples already kill this. Also we can adjust the parameters to make  tiny and one wonders if then (**) follows from the new results by Michael and Nets.
tiny and one wonders if then (**) follows from the new results by Michael and Nets.
Comment by Gil Kalai — February 20, 2011 @ 7:22 pm |
Gil, are you prepared to make public the proof that the conjecture implies the bound you say? Or is it meant to be an easy exercise? (Just staring at it I feel a bit mystified, but perhaps if I made a serious attempt to prove the implication — and not in my head — I would realize that it was not too hard.) Or is it possible to give a sketch that makes the implication seem reasonable?
Comment by gowers — February 22, 2011 @ 12:08 pm |
Sure, here it is: http://www.ma.huji.ac.il/~kalai/line5.pdf
Comment by Gil Kalai — February 22, 2011 @ 9:28 pm |