The proposal “deterministic way to find primes” is not officially a polymath yet, but is beginning to acquire the features of one, as we have already had quite a bit of interesting ideas. So perhaps it is time to open up the discussion thread a little earlier than anticipated. There are a number of purposes to such a discussion thread, including but not restricted to:
- To summarise the progress made so far, in a manner accessible to “casual” participants of the project.
- To have “meta-discussions” about the direction of the project, and what can be done to make it run more smoothly. (Thus one can view this thread as a sort of “oversight panel” for the research thread.)
- To ask questions about the tools and ideas used in the project (e.g. to clarify some point in analytic number theory or computational complexity of relevance to the project). Don’t be shy; “dumb” questions can in fact be very valuable in regaining some perspective.
- (Given that this is still a proposal) To evaluate the suitability of this proposal for an actual polymath, and decide what preparations might be useful before actually launching it.
To start the ball rolling, let me collect some of the observations accumulated as of July 28:
- A number of potentially relevant conjectures in complexity theory and number theory have been identified: P=NP, P=BPP, P=promise-BPP, existence of PRG, existence of one-way functions, whether DTIME(2^n) has subexponential circuits, GRH, the Hardy-Littlewood prime tuples conjecture, the ABC conjecture, Cramer’s conjecture, discrete log in P, factoring in P.
- The problem is solved if one has P=NP, existence of PRG, or Cramer’s conjecture, so we may assume that these statements all fail. The problem is probably also solved on P=promise-BPP, which is a bit stronger than P=BPP, but weaker than existence of PRG; we currently do not have a solution just assuming P=BPP, due to a difficulty getting enough of a gap in the success probabilities.
- Existence of PRG is assured if DTIME(2^n) does not have subexponential circuits (Impagliazzo-Wigderson), or if one has one-way functions (is there a precise statement to this effect?)
- Discrete log being in hard (or easy) may end up being a useless hypothesis, since one needs to find large primes before discrete logarithms even make sense.
- The problem is solved if one has P=NP, existence of PRG, or Cramer’s conjecture, so we may assume that these statements all fail. The problem is probably also solved on P=promise-BPP, which is a bit stronger than P=BPP, but weaker than existence of PRG; we currently do not have a solution just assuming P=BPP, due to a difficulty getting enough of a gap in the success probabilities.
- If the problem is false, it implies (roughly speaking) that all large constructible numbers are composite. Assuming factoring is in P, it implies the stronger fact that all large constructible numbers are smooth. This seems unlikely (especially if one assumes ABC).
- Besides adding various conjectures in complexity theory or number theory, we have found some other ways to make the problem easier:
- The trivial deterministic algorithm for finding k-bit primes takes exponentially long in k in the worst case. Our goal is polynomial in k. What about a partial result, such as exp(o(k))?
- An essentially equivalent variant: in time polynomial in k, we can find a prime with at least log k digits. Our goal is k. Can we find a prime with slightly more than log k digits?
- The trivial probabilistic algorithm takes O(k^2) random bits; looks like we can cut this down to O(k). Our goal is O(log k) (as one can iterate through these bits in polynomial time). Can we do o(k)?
- Rather than find primes, what about finding almost primes? Note that if factoring is in P, the two problems are basically equivalent. There may also be other number theoretically interesting sets of numbers one could try here instead of primes.
- The trivial deterministic algorithm for finding k-bit primes takes exponentially long in k in the worst case. Our goal is polynomial in k. What about a partial result, such as exp(o(k))?
- At the scale log n, primes are assumed to resemble a Poisson process of intensity 1/log n (this can be formalised using a suitably uniform version of the prime tuples conjecture). Cramer’s conjecture can be viewed as one extreme case of this principle. Is there some way to use this conjectured Poisson structure in a way without requiring the full strength of Cramer’s conjecture? (I believe there is also some work of Granville and Soundarajan tweaking Cramer’s prediction slightly, though only by a multiplicative constant if I recall correctly.)
See also the wiki page for this project.

This project is moving faster than I had thought, so I have quickly whipped up a wiki page for it:
http://michaelnielsen.org/polymath1/index.php?title=Finding_primes
Also, it looks like we will have to launch this particular polymath well before October… any thoughts on the pros and cons on “officially” making this a polymath (e.g. polymath4, since Gil has claimed the Hirsch conjecture for polymath3) in the near future? I can act as a moderator, though I will need some assistance in the short term as I will be travelling starting today for the next few days.
Comment by Terence Tao — July 28, 2009 @ 3:33 pm |
I’ve just announced this blog publicly on my own blog, so I expect activity on this project to increase even more in the near future… I was sort of hoping for a slow, controlled rollout of this project, but it seems that these things have a life of their own, and essentially only operate at one speed (fast).
So we’ll have to play catch-up. One thing that needs to be done soon is to improve the wiki page so that people can join in more easily. For instance, this project is going to throw around a lot of conjectures in both computational complexity (e.g. P=BPP) as well as analytic number theory (e.g. prime tuples conjecture). One immediate project would be to flesh out the list of such conjectures already on the wiki with some links, either to external sites (e.g. Wikipedia) or some internal page that will explain all the jargon that is being thrown around.
In the meantime, please use this thread to ask “dumb” questions (e.g. “What is BPP?”), especially if their answer is likely to be clarifying to other casual participants of this blog.
The other thing is that this is likely to be my last post for four or five days as I will shortly travel overseas. Given the experience with minipolymath I know that a leadership vacuum can be damaging to a polymath project, so I hope people will take the initiative and step in to organise things if necessary. (Tim Gowers, Gil Kalai, and Michael Nielsen are also administrating this blog and may be able to help out with technical issues, e.g. editing a comment, or empowering a moderator to edit comments.)
Comment by Terence Tao — July 28, 2009 @ 4:34 pm |
If this does turn into a polymath project by default — which is OK by me as it’s a problem I’d very much like to see solved — can I strongly urge that the start is delayed for a week or two? I have a selfish and an altruistic reason for this. (I seem to remember having written precisely that sentence somewhere else recently.) The selfish reason is that I’ll be on an internet-free holiday for the whole of next week. The more serious reason is that I’m sure I’m not the only one who gets rapidly lost when theoretical computer scientists drop names of complexity classes all over the place. I don’t know how they do it, but they seem to know what they all are, and how they are related to each other (either actually or conjecturally). I can see myself getting rapidly left behind, or at least left behind from parts of the conversation, unless some serious work is put in first in order to get a good wiki going that explains, informally but in detail and with good examples, what all the various conjectures from complexity theory and from number theory are.
Comment by gowers — July 28, 2009 @ 4:40 pm |
Fortunately, there is already such a wiki that lists and explains almost all complexity classes known to mankind: http://qwiki.stanford.edu/wiki/Complexity_Zoo
As an example, on PromiseBPP is says:
“Same as PromiseRP, but for BPP instead of RP.”
And then on PromiseRP it says:
“The class of promise problems solvable by an RP machine. I.e., the machine must accept with probability at least 1/2 for “yes” inputs, and with probability 0 for “no” inputs, but could have acceptance probability between 0 and 1/2 for inputs that do not satisfy the promise. “
Comment by Wim vam Dam — July 28, 2009 @ 4:59 pm |
For senile mathematicians like me, that isn’t enough. I need to be given some examples of problems in BPP, RP, PromiseBPP, etc., together with informal explanations of why they are in those classes. Otherwise, I just don’t have any confidence that I understand what I have read.
Comment by gowers — July 28, 2009 @ 5:24 pm |
[Airport has internet, yay!]
Given that I’m also going to be largely internet-free next week, a delay of a week or more does sound desirable. I think what I will do is put a note on the research thread asking people not to work too hard on the problem for now, though clearly if a useful thought comes to mind and it is solid enough to be of immediate value to other participants, it is still worthwhile to record it. Meanwhile, we can focus efforts on building the wiki with some good exposition, particularly with regard to complexity classes, which seem to be particularly relevant for this project. I’m imagining taking a highly specialised subslice of the Complexity Zoo and expanding it on the wiki in a way aimed at complexity theory novices (with emphasis on examples, relationship to the prime finding problem, etc.)
Comment by Terence Tao — July 28, 2009 @ 7:00 pm |
I’ll gladly do some of that — in fact, I might start this evening.
Comment by gowers — July 28, 2009 @ 7:33 pm |
I’d be happy to take a crack at contributing on this problem, but it seems like a bit of a “scary” one for a Polymath project. By this I mean that it’s a problem that’s been around for a while but I haven’t heard of many attacks on it. (Perhaps we should ask Manindra/Neeraj/Nitin if they spent time on it…)
Contrast this with Primality, which *did* have a fair bit of partial progress before its dramatic solution (e.g., n^{log log log n} time algorithm, poly-time algorithm assuming RH, in NP, in RP, in co-RP, Agrawal-Biswas).
Perhaps a less scary question in a similar vein is that of factoring (univariate) polynomials over finite fields. It has long been known that this has a randomized poly-time algorithm (by poly, we mean poly(n, log p) for factoring degree-n polynomials over F_p), and it is still unknown if this can be derandomized. I’m not sure what the current state of the art is, but I’m pretty sure there’s been a steady drip of work on special cases, how to use fewer than expected random bits, what you can get if you assume ERH, average-case analysis, and so forth. Might be easier for Polymath to get some traction on this problem.
Comment by Ryan O'Donnell — July 29, 2009 @ 6:34 am |
Ryan, I sort of agree with you, and certainly the problem you suggest sounds like a very good one to try. But in a way I’m quite interested to see what the result will be if this problem turns into a fully-fledged Polymath project. It does feel “too difficult” somehow, but for that very reason it could be a very useful experiment in understanding what Polymath can and cannot achieve. My guess is that there would be a lot of initial discussion, with many interesting ideas proposed and briefly explored, and that after a shortish time like two or three weeks it would begin to feel as though we were going round in circles. But even if that happened, I think we could aim to produce a very interesting wiki that served as a summary of the thoughts that had taken place. And there is always the chance that the prediction I’ve just made is wrong: perhaps some piece of magic would happen and a serious result (not necessarily a solution to the original problem, but something related) would get proved. Either way, we would have valuable new information about Polymath projects in general.
This isn’t a knock-down argument of course — maybe there are other projects that would yield more information of this kind more efficiently. But I think this one should be at least reasonably efficient, since either my prediction is right (in which case either the project lasts a short time or it leads to something very good) or it is wrong (in which case something unexpected has happened and we’ve learned more about Polymath).
I definitely think we should bear in mind that polynomial-factoring question though. Another question is whether we should keep that as an entirely separate project, or whether it should be part of the discussion about finding primes. For what it’s worth, I’d vote for keeping it separate.
Comment by gowers — July 29, 2009 @ 7:30 am |
By the way, it was pointed out to me today by Sergey Yekhanin and others that the polynomial factorization problem is open even in the case of degree 2, in which case it is equivalent to the problem of deterministically finding a quadratic nonresidue in F_p in time polylog(p) — and that this is a notorious open problem in algorithmic number theory.
Comment by Ryan O'Donnell — July 30, 2009 @ 7:18 am |
[…] also the discussion thread for this proposal, which will also contain some expository summaries of the comments below, as well as the wiki page […]
Pingback by Proposal: deterministic way to find primes « The polymath blog — July 31, 2009 @ 5:12 am |
An unlikely idea, but maybe a polymath project is just the right place to throw it into the discussion: Recently Viola, Bogdanov, Lovett, et al. have made progress on unconditional PRGs that fool constant-degree polynomials over finite fields. So, if the AKS primality test could be reformulated in this model of computation, i.e. as a constant-degree d polynomially-sized polynomial AKS: {0,1}^n –> {0,1}, the problem would be solved for any fixed n.
Comment by Martin Schwarz — July 31, 2009 @ 4:10 pm |
I’ll have a crack at trying to summarise some of the progress of the last few days, which is part of what this discussion thread is for; feel free to expand upon this update.
* The wiki page is slowly being updated. Please take a look at it and see if there are any quick contributions you can add (e.g. adding new papers, concepts, etc.) Don’t be shy; we can always edit the content later, but the key thing is to have the content there in the first place.
* It looks like we’re not going to solve the problem just by soft complexity theory techniques; in the language of Impagliazzo, we have one way to find primes in “Algorithmica” (and maybe “Heuristica”) type worlds, in which we can solve NP type problems easily, and we have another way to find primes in “Minicrypt” or “Cryptomania” type worlds where we have good pseudorandom generators to derandomise the probabilistic algorithm, but there is this nasty middle world of “Pessiland” where we don’t have good tools.
* The function field version is known (a result of Adelman-Lenstra).
* If factoring is cheap, then it would suffice to find a short interval (or other small, easily explored set) which contains a non-smooth number. There is a chance that additive combinatorial techniques (applied to iterated sumsets of logarithms of primes) could be relevant here. There is also a substantial number theory literature on smooth numbers that should be looked into, although most of the focus is on getting smooth numbers rather than non-smooth numbers. (I tried to apply the ABC conjecture to rule out large consecutive strings of smooth numbers, but it looks like it is not the right tool – the smooth numbers don’t need to have repeated prime factors and so one gets little gain from ABC.)
I probably missed some stuff; feel free to add, correct, or elaborate.
Comment by Terence Tao — July 31, 2009 @ 7:51 pm |
[…] https://polymathprojects.org/2009/07/28/deterministic-way-to-find-primes-discussion-thread/ […]
Pingback by Upcoming polymath project « Euclidean Ramsey Theory — August 2, 2009 @ 4:39 pm |
This could be interesting http://mathworld.wolfram.com/PrimeDiophantineEquations.html. Are there any approach based on Diophantine representation?
Comment by Anonymous — August 3, 2009 @ 5:12 pm |
Hmm. Well, by Matiyasevich, any recursively enumerable set (not just the primes) can be described via Diophantine equations. We know that the problem of finding primes quickly becomes impossible if one replaces the primes with other recursively enumerable sets (e.g. the set of high-complexity numbers), so it seems unlikely that one could proceed purely by Diophantine equation theory, but will have to use something specific about the primes.
Comment by Terence Tao — August 5, 2009 @ 2:03 am |
An update on the recent discussion:
* We have a couple of negative results and heuristics that seem to rule out some types of approaches. For instance, we can’t use any soft complexity theory argument that doesn’t explicitly use some special property of the primes (besides the fact that they are dense and testable) because there are sets of “pseudoprimes” which are dense and testable (assuming an oracle) but which cannot be located deterministically. (See this page for details.) On the other hand, this objection disappears if a factoring oracle is assumed.
* In a similar spirit, if we delete all the “constructible” primes from the set of primes, leaving only the “generic” primes, then the conjecture fails, while leaving all average-case results about primes (and some worst-case results too) intact. So it is unlikely that one can proceed purely by using average-case results about primes. Though again, this objection may disappear if a factoring oracle is assumed.
* Using sieve theory to find non-smooth numbers also seems problematic. The problem is that sieve theory is largely insensitive to the starting point of an interval. Since the interval [1,x] contains nothing but x-smooth numbers, it is thus not possible to use sieve theory to locate non x-smooth numbers in any other interval of length x. In particular, this suggests that sieves and factoring oracles cannot be used to locate primes larger than x without searching through more than x numbers.
* The smallest explicit set known which is guaranteed to contain a number with a prime factor of at least x is of size about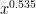 (unconditionally) or
(unconditionally) or  (assuming GRH), and is basically just an interval. Can one do better? There are some polynomial forms (
(assuming GRH), and is basically just an interval. Can one do better? There are some polynomial forms (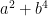 and
and 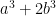 ) that are known to capture their primes, but can they be made sparser? (It may become necessary to start a reading seminar on Friedlander-Iwaniec at some point.)
) that are known to capture their primes, but can they be made sparser? (It may become necessary to start a reading seminar on Friedlander-Iwaniec at some point.)
* Tim’s proposal to try to use additive combinatorics to show that non-smooth numbers are so uniformly distributed that they lie in every short interal (comment #18 in the research thread) remains untouched so far by the above objections; hopefully when Tim gets back from his vacation we can analyse it more thoroughly.
* There seems to be a fundamental barrier that in order to deterministically find an integer that avoids m different congruence relations, one has to search at least m+1 different numbers. Thus, for instance, to find a number not divisible by any prime less than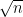 , one needs to search about
, one needs to search about 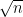 numbers, which is consistent with the fact that even assuming GRH, we currently need about
numbers, which is consistent with the fact that even assuming GRH, we currently need about 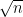 searches to deterministically obtain a prime of size n. It would be good to find a way to substantially break this barrier. (For small moduli one can use the Chinese remainder theorem to concatenate some moduli, but if searching for numbers of size n, one can only apply this theorem to about
searches to deterministically obtain a prime of size n. It would be good to find a way to substantially break this barrier. (For small moduli one can use the Chinese remainder theorem to concatenate some moduli, but if searching for numbers of size n, one can only apply this theorem to about 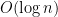 of the moduli.)
of the moduli.)
* It may be that even the very weakest of the conjectures (e.g. beating the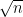 barrier for deterministically finding a prime larger than n, assuming a factoring oracle) may be beyond the ability to solve without powerful number theory or complexity conjectures. However, it may still be instructive to try to collect reasons why the problem is difficult (i.e. add to the list of obstructions mentioned above).
barrier for deterministically finding a prime larger than n, assuming a factoring oracle) may be beyond the ability to solve without powerful number theory or complexity conjectures. However, it may still be instructive to try to collect reasons why the problem is difficult (i.e. add to the list of obstructions mentioned above).
* The research thread is getting very long. I guess it should soon be time to officially open the polymath project and start a fresh thread, summarising some of the key insights so far. I might do this in a week or so (I know Tim wanted to hold off until he’s back from vacation).
Comment by Terence Tao — August 5, 2009 @ 4:56 pm |
Let me inaugurate the asking of dumb questions with a request and a comment. First, could someone make an attempt at summarizing Gowers’ combinatorial idea (related to post 18), I don’t entirely follow it.
Secondly, I have a (rather obvious) comment. There seems to be several strategies of the form, “we can assume that conjectures X, Y and Z don’t hold, for otherwise we can solve the problem”. For example, we may assume that Cramer’s conjecture fails and P != NP. However, if we can succeed under these hypothesis, then it seems likely we will obtain an existence proof without an explicit algorithm. For example, we won’t have access to the supposed polynomial algorithm implied by the assumption that P=NP, although our solution would be based on running that algorithm. If we assume, say, Cramer’s conjecture then we have a very simple algorithm (we just start searching through the k-digit numbers) however if we don’t know the implied constant in expression O(ln^2(k)) then we have no idea how long it will take our algorithm to terminate. I would be very eager to even see an existence proof, but would such a proof really have any advantage over the random polynomial algorithm?
Comment by Anon — August 6, 2009 @ 9:30 pm |
Thanks for “breaking the ice”, as it were!
Tim’s idea goes something like this. We want to find a prime with at least k digits. If we assume a factoring oracle, it’s enough to find a non-smooth number, or more precisely a number containing at least one prime factor with at least k digits. The idea is then to look at some interval [n,n+a] (with n much larger than , and
, and  represents the “cost budget” for the search – polynomial in k for the strong conjecture,
represents the “cost budget” for the search – polynomial in k for the strong conjecture,  for the weak conjecture) – the exact tuning of parameters is one of the things that will have to be done at some point) and factor all of them, hoping to find a large prime.
for the weak conjecture) – the exact tuning of parameters is one of the things that will have to be done at some point) and factor all of them, hoping to find a large prime.
The only way this will fail is if none of the numbers in [n,n+a] have prime factors with at least k digits. In particular, if one lets J be the set of all primes with k digits, then the iterated power sets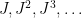 of J are going to completely miss [n,n+a]. If we let K be the logarithms of the elements in J, this means that the iterated sumsets
of J are going to completely miss [n,n+a]. If we let K be the logarithms of the elements in J, this means that the iterated sumsets 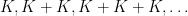 completely miss
completely miss ![[\log n, \log(n+a)]](https://s0.wp.com/latex.php?latex=%5B%5Clog+n%2C+%5Clog%28n%2Ba%29%5D&bg=ffffff&fg=000000&s=0&c=20201002) .
.
On the other hand, there are a number of results in additive combinatorics which have the general flavour that repeated sumsets tend to spread out very “uniformly”, unless they are concentrated in an arithmetic progression. If all the parameters are favourable, the hope is then that one can use the additive combinatorics machinery to show that iterated sumsets will hit![[\log n, \log (n+a)]](https://s0.wp.com/latex.php?latex=%5B%5Clog+n%2C+%5Clog+%28n%2Ba%29%5D&bg=ffffff&fg=000000&s=0&c=20201002) unless K is concentrated on an arithmetic progression, so that J is concentrated on or near a geometric progression, which perhaps can be ruled out by number-theoretic means.
unless K is concentrated on an arithmetic progression, so that J is concentrated on or near a geometric progression, which perhaps can be ruled out by number-theoretic means.
It may well be that the parameters are such that this doesn’t work, but I think there is a non-zero chance of success, especially if one is willing to settle for the weak conjecture or even just to beat the current world record of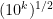 . I’m thinking of making the exploration of the feasibility of Tim’s idea one of the main focuses of the polymath project when it formally launches.
. I’m thinking of making the exploration of the feasibility of Tim’s idea one of the main focuses of the polymath project when it formally launches.
As for your second comment, there is a standard observation (which I guess I should have made explicitly, but I put it on the wiki) that if a polynomial-time algorithm to achieve a task (in this case, to find a prime), then an explicit polynomial-time algorithm to achieve the same task also exists. The idea is basically to run all the possible polynomial-time algorithms in parallel. More precisely, if one enumerates all the possible algorithms in the world as , then what one can do is, for each i, run each of the algorithms
, then what one can do is, for each i, run each of the algorithms  for time
for time 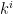 , then increment i and keep going. This will terminate successfully in polynomial time if even just oen of the algorithms
, then increment i and keep going. This will terminate successfully in polynomial time if even just oen of the algorithms 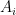 finds a prime in polynomial time. It’s sort of a sleazy trick, but this is, technically, an explicit algorithm. (My guess, though, it will be relatively easy to extract a more elegant algorithm out of any positive result that we actually end up obtaining, even if it is initially conditional in nature.)
finds a prime in polynomial time. It’s sort of a sleazy trick, but this is, technically, an explicit algorithm. (My guess, though, it will be relatively easy to extract a more elegant algorithm out of any positive result that we actually end up obtaining, even if it is initially conditional in nature.)
I should also point out that this problem is primarily of pure mathematical interest, given that the current probabilistic methods to find primes are quite satisfactory. See also this post by Lance Fortnow on this project.
Comment by Terence Tao — August 6, 2009 @ 11:10 pm |
“So, given sufficiently strong conjectures in complexity theory (I don’t think P=BPP is quite sufficient, but there are stronger hypotheses than this which would work), one could solve the problem.”
Maybe I overlook something simple but what specific conjecture in complexity theory will solve the problem positively?
Another question: I wonder what is the algorithmic status of other related problems regarding gaps of primes. (Even not worrying too much about randomized algorithms.) a) Finding large gaps between primes (Rankin and related results), b) finding primes with small gaps (Goldon-Pintz-Yildirim), c) finding AP of length 3 of at least k-digits primes (Green-Tao)
If we allow Cramer-model based conjectures I suppose we have deterministic polynomial algorithm for all these as well as for d) find k-digits twin primes. But these are extremely strong conjectures.
Also I wonder if the little advantage we gained by allowing factoring oracles disappears at once for all these variants.
Comment by Gil Kalai — August 8, 2009 @ 11:25 am |
Well, as Lance further explained on his blog there is a concrete conjecture referred to as full derandomization that implies that the there is a polynomial time deterministic algorithm for finding primes
http://blog.computationalcomplexity.org/2006/07/full-derandomization.html
The (very strong) conjecture is stated in terms of Hardness and is related to Hardmess vs randomization theme in CC. http://cseweb.ucsd.edu/~russell/survey.ps
Comment by Gil Kalai — August 8, 2009 @ 3:59 pm |
Well, with regards to (c) [finding AP of primes] the number of AP are dense enough that one can just randomly take arithmetic progressions of k-digit numbers and check them for primality and one will probably get a hit in polynomial time.
Similarly, for (b) (primes with small gap), assuming GUE one has Poisson type statistics for prime gaps, and so one will get a prime gap much smaller than log n just by searching randomly. Or, one can just go for the gold and search for twin primes randomly, though of course this is conditional on the twin prime conjecture (with the expected asymptotic, or at least a comparable lower bound.) Unconditionally, I think it’s open, because the GPY results only give a very sparse set of small prime gaps. Similarly for the Rankin results in (a).
I quite like the problem you proposed in the other thread, to find adjacent pairs n, n+1 of square-free numbers. Such pairs exist in abundance (since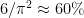 of all numbers are square-free) but there is no obvious way to generate them. As square-free numbers seem to be substantially more “elementary” than primes, this may well be a good toy problem (and has some of the same flavour, namely trying to avoid a large number of residue classes at once, though the number of residue classes to avoid is much sparser than that of the primes (note that
of all numbers are square-free) but there is no obvious way to generate them. As square-free numbers seem to be substantially more “elementary” than primes, this may well be a good toy problem (and has some of the same flavour, namely trying to avoid a large number of residue classes at once, though the number of residue classes to avoid is much sparser than that of the primes (note that  converges, while
converges, while  does not) so this is presumably an easier problem to solve.
does not) so this is presumably an easier problem to solve.
In a few days I plan to launch the finding primes project formally as polymath4 (polymath3 being claimed by the Hirsch conjecture), in part because the current research thread is getting bloated. I think I will put the square-free problem as one of the toy problems to consider.
Comment by Terence Tao — August 8, 2009 @ 4:48 pm |
My questions regarding (a) (b) and (c) is what can be proved without assuming any conjectures…
Comment by Gil — August 8, 2009 @ 6:03 pm |
Possible approach.
To generate lots adjacent pairs of square-free numbers with reasonable probability, note that one of the numbers has to be even. So construct even square-free numbers by multiplying small primes including 2 (to get an even one) and test the numbers either side – depends on having a good test for square-freeness, but factoring will do this.
Comment by Mark Bennet — August 8, 2009 @ 6:19 pm |
We might be able to make some progress on the square-free problem from a well-known conjecture regarding Sylvester’s sequence. Sylvester’s sequence is defined by the recurrence: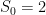
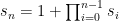 . It is conjectured (and there is numerical evidence to support this) that every element of this sequence is square-free. Additionally, it isn’t hard to show that the numbers
. It is conjectured (and there is numerical evidence to support this) that every element of this sequence is square-free. Additionally, it isn’t hard to show that the numbers 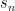 are coprime. To see this note that for every
are coprime. To see this note that for every 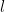 <
<  we have that
we have that  . On the conjecture, we then would have that
. On the conjecture, we then would have that  and
and 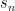 are both square-free. We should also (I think) be able to quickly compute the sequence from the recurrence. One interesting caveat is that the sequence grows double-exponentially, so it wouldn't (at least directly) give a square-free number of
are both square-free. We should also (I think) be able to quickly compute the sequence from the recurrence. One interesting caveat is that the sequence grows double-exponentially, so it wouldn't (at least directly) give a square-free number of  -digits for every
-digits for every  .
.
Comment by Mark Lewko — August 9, 2009 @ 12:04 am |
[…] which has now become rather lengthy. (Simultaneously with this research thread, we also have the discussion thread to oversee the research thread and to provide a forum for casual participants, and also the wiki […]
Pingback by (Research thread II) Deterministic way to find primes « The polymath blog — August 9, 2009 @ 4:00 am |
[…] be explored soon. In addition to this thread, there is also the wiki page for the project, and a discussion thread aimed at more casual participants. Everyone is welcome to contribute, as always. Possibly related […]
Pingback by Polymath4 (”Finding Primes”) now officially active « What’s new — August 9, 2009 @ 4:35 am |
A few comments:
1) About the shortest interval which guarantees primes: The 0.535 can be replaced by 0.525.
Proceedings of the London Mathematical Society 83, (2001), 532–562.
R. C. Baker, G. Harman and J. Pintz, The difference between consecutive primes, II
The authors sharpen a result of Baker and Harman (1995), showing that [x, x + x^{0.525}] contains prime numbers for large x.
2) About question 28 by Gil, 5th August:
2a) In addition to Terry’s reference to Schinzel’s Hypothesis H, saying that irreducible polynomials take infinitely many prime values, unless there is an obvious reason why not: a quantitive version of Schinzel’s conjecture is called “Bateman-Horn conjecture”,
giving the density c_f/log X, where the constant c_f depends on the polynomial, and also predicting densities for k-tuples.
http://en.wikipedia.org/wiki/Bateman-Horn_conjecture
2b) An elementary way to see that an arithmetic progression cannot contain too many primes is:
The sum over the reciprocals of the AP: Sum_{k < X} 1/(ak+b) grows like (log X)/a, whereas the sum of the reciprocals of primes p<X grows like log log X only. So the density of the primes in the AP must be zero.
Comment by Christian Elsholtz — August 9, 2009 @ 9:22 am |
Can we have examples/counterexamples, whereever possible, that illustrate how a conjecture/theorem holds/does not hold
Comment by tful — August 9, 2009 @ 4:35 pm |
Is there a specific result or conjecture on the wiki or elsewhere that you have in mind? I guess I’m asking for an example for where an example is needed. :-)
Comment by Terence Tao — August 10, 2009 @ 10:27 pm |
(I’m posting this here because after I thought of it, I could hardly not post it, but it’s incredibly silly and should probably not clutter up the research thread.)
I have a simple deterministic algorithm, with a 19th-century analytic NT flavor, that essentially finds a prime of at least n bits in time roughly linear in n (assuming an oracle for primality, of course.)
First, pick an arbitrary n-bit integer; there are a number of ways to do this in the literature. Then, check the next O(n) odd integers for primality. If one of them is prime, we’re done; if not, pick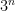 ; since prime powers can for the interesting purposes be considered essentially the same as the primes, we have essentially found a prime.
; since prime powers can for the interesting purposes be considered essentially the same as the primes, we have essentially found a prime.
(P.S. Yes, I realize that “prime powers can be considered essentially primes” is a criminal oversimplification, but there are situations — in particular the proof of the PNT — where it’s true and useful, and once I thought of this bad joke it wouldn’t get out of my head.)
Comment by Harrison — August 11, 2009 @ 11:11 am |
I have a question of procedure. To improve my own understanding I’ve been working on some notes about a proof of Bertrand’s postulate. I was imagining posting these to the wiki (and cross-posting to my blog) as background material. However, it occurs to me to wonder how that fits with the spirit of “small increments”. I would perhaps suggest that the small increments philosophy only need apply to the research and writeup, not necessarily to the preparation of background materials for the wiki. But I wanted to run this by others in case they see a problem or disagree.
Comment by Michael Nielsen — August 11, 2009 @ 5:58 pm |
Well, from previous polymath experiences I think that the “small increments” philosophy is mostly applicable to the type of work which _can_ be divided up into small increments; there are some tasks which really do need someone to go away and work for an hour, and it seems counterproductive to ask that such tasks be prohibited or that it is somehow split up into five-minute chunks. It seems that we are approaching the point where detailed computations need to be made, but as long as people aren’t spending entire days offline trying to crack the whole thing, I think we’re still adhering to the spirit of the polymath project. (But it was courteous to notify the rest of us what you are doing.)
Comment by Terence Tao — August 11, 2009 @ 7:02 pm |
Wow, there is so much activity in the research that it is hard to keep up! I am going to try to summarise some of the discussion, and to put it on the wiki. This may take a while though…
We seem to be considering quite a few distinct strategies:
1. Studying iterated sumsets of log-primes (Gowers #I.18, Tao #3, Gowers #7, #17), which now looks like it has hit some fundamental obstructions (Kalai #36, Gowers #38);
2. Studying signed sums of prime reciprocals (Croot #10), which still looks promising but needs further analysis;
3. Computing pi(x) and using Riemann zeroes (Kowalski #28, Croot #35, PhilG #37) – I haven’t digested this thread yet, but will try to soon.
4. Demonstrating the existence of a factored number near n by repeated adjustments (Gowers #13, #16, #21). May also be subject to the obstructions to 1.
5. Finding pseudoprimes first (Wigderson #18, Kalai #22)
6. Analysing special sequences, e.g. Sylvester sequence (Lewko #2, Dyer #24)
7. Lattice strategies for the adjacent square-frees (or nearby square-frees) problem (Croot #29). May be subject to the same objections to 1.
There’s also some progress in clarifying the role (or lack thereof) of P=BPP (Trevisan #34)
There are now multiple indications that the square root barrier (beating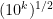 ) is quite a serious one. Perhaps we should lower our sights still further and shoot for the “ultraweak” conjecture of finding a prime larger than
) is quite a serious one. Perhaps we should lower our sights still further and shoot for the “ultraweak” conjecture of finding a prime larger than  in time
in time  .
.
We’ve also realised that to get a non-smooth number in a small interval one cannot use average-case information about the set of all primes, because most primes will not actually divide into a number in that small interval, and if one deletes the few primes that do, then this is not detectable in the average-case statistics (unless the size of the interval exceeds the square root barrier). This type of problem seems to kill strategy 1., and may also seriously injure strategies 4 and 7.
More updates later, hopefully… in the meantime I will try incorporating the recent progress into the wiki.
Comment by Terence Tao — August 12, 2009 @ 3:35 pm |
Incidentally, I have a post on my own blog on the AKS primality test at
which may be of relevance. Somewhat more whimsically, XKCD seems to also be contributing to the project with its latest comic:
http://www.xkcd.com/622/
Comment by Terence Tao — August 12, 2009 @ 3:55 pm |
The research thread has passed 120 comments now… is it time to start a new thread?
I realised that maybe we can use the ratings system to answer this question efficiently… one can use the ticks or crosses below this comment to vote on whether it is time to start afresh and try to summarise the progress so far (tick), or continue with the thread as is (cross). Of course, one can also make comments in the more traditional way.
Comment by Terence Tao — August 12, 2009 @ 9:01 pm |
[…] always, oversight of this research thread is conducted at the discussion thread, and any references and detailed computations should be placed at the wiki. Leave a […]
Pingback by (Research Thread III) Determinstic way to find primes « The polymath blog — August 13, 2009 @ 5:13 pm |
This is regarding my most recent reply to post #7 on research III. I got a bit caught up in the verifications and I didn’t realize just how long this description ended up being. This clearly belongs in the wiki and not on the research thread. Mea culpa!
If possible, I would like some assistance to declutter the research thread and move this where it belongs on the wiki. I will also add a description of the systems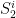 and
and  for context.
for context.
Comment by François Dorais — August 15, 2009 @ 3:25 am |
Dear Francois,
It does seem like a good idea to put lengthier or more technical computations on the wiki. If you do so, you can put a new comment giving the link and a summary of the contents next to your previous comments and I can then remove any obsolete comments.
Comment by Terence Tao — August 15, 2009 @ 3:04 pm |
The poor formatting of my post #15 with all those line-breaks in strange places makes me wonder: is there a way to set up wordpress so that it is possible to “preview” a submission before actually submitting it?
Comment by Albert Atserias — August 17, 2009 @ 3:45 pm |
I fixed the problem manually. I think it is possible to install a previewing feature, but we would have to use a customised installation of wordpress rather than relying on wordpress.com’s free platform as they explicitly disallow preview for security reasons, as stated here:
http://en.forums.wordpress.com/topic.php?id=7517&page&replies=4
Certainly, if and when we migrate to a more optimal platform, this is one of the features we will want to have.
Comment by Terence Tao — August 17, 2009 @ 3:51 pm |
I’m wondering why the idea of trying to generate numbers that satisfy the AKS congruences and variants has received very little (visible) attention so far. Admittedly this looks like a very difficult problem, but it has many advantages over “pure” divisibility/density based approaches. An important advantage is that such congruences are apparently “razor-proof”. More generally, you can’t delete an arbitrary “thin-but-large” set of (pseudo-)primes and expect the resulting set to be polytime recognizable. Maybe I missed something that rules out this method?
Comment by François Dorais — August 18, 2009 @ 7:08 pm |
Well, I tried a little to get somewhere, but even the Fermat congruences such as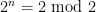 seem hard to catch, let alone the stronger AKS congruences [of which the Fermat congruences are the constant term]. (There is the classical observation that if n is a pseudoprime wrt 2, then
seem hard to catch, let alone the stronger AKS congruences [of which the Fermat congruences are the constant term]. (There is the classical observation that if n is a pseudoprime wrt 2, then 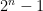 is also, but this doesn’t seem to extend to, say, give a simultaneous pseudoprime wrt 2 and 3.) Part of the problem is that the quantity
is also, but this doesn’t seem to extend to, say, give a simultaneous pseudoprime wrt 2 and 3.) Part of the problem is that the quantity 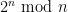 seems to obey no useful properties as n varies; the exponentially large nature of the quantity which one is seeking the remainder of seems to defeat most naive approaches to the problem.
seems to obey no useful properties as n varies; the exponentially large nature of the quantity which one is seeking the remainder of seems to defeat most naive approaches to the problem.
The one thought I had was that it may be possible to apply the AKS algorithm to several integers n in parallel by recycling some steps, which could shave a log factor or two off of the best deterministic algorithm (if we insist on computing primality by AKS, rather than assuming a O(1)-time oracle), but this is perhaps not very exciting.
Comment by Terence Tao — August 18, 2009 @ 8:57 pm |
It does look like a very difficult problem. I thought that understanding a little about the function might help. The only idea I got toward this is the following. Expanding
might help. The only idea I got toward this is the following. Expanding
and looking at the solutions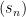 of the linear recurrence
of the linear recurrence
with and
and  , then the multiples of
, then the multiples of 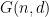 are precisely the set of possible values of
are precisely the set of possible values of 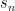 . I tried to use some linear recurrence technology (which I don’t know very well) to get some information about
. I tried to use some linear recurrence technology (which I don’t know very well) to get some information about 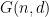 but I didn’t get anywhere. Anyway, I just wanted to throw that out there in case somebody might find this useful…
but I didn’t get anywhere. Anyway, I just wanted to throw that out there in case somebody might find this useful…
Comment by François Dorais — August 19, 2009 @ 1:28 am |
This is not directly relevant to the finding primes project, but I also thought about deconstructing the proof that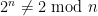 implies that n is composite to see if it could give a factoring algorithm. The problem is that the proof of the implication requires poly(n) arithmetic operations (to get from the bijectivity of
implies that n is composite to see if it could give a factoring algorithm. The problem is that the proof of the implication requires poly(n) arithmetic operations (to get from the bijectivity of 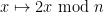 when n is odd to the fact that
when n is odd to the fact that 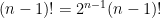 requires poly(n) applications of the associative law, and dividing out by (n-1)! requires a further n operations if one wants to be sure that one is not dividing by zero) so does not suggest any algorithm for factoring that is not exponentially large in the number of digits.
requires poly(n) applications of the associative law, and dividing out by (n-1)! requires a further n operations if one wants to be sure that one is not dividing by zero) so does not suggest any algorithm for factoring that is not exponentially large in the number of digits.
Comment by Terence Tao — August 18, 2009 @ 9:02 pm |
I’m glad you thought about doing that. I believe it is still an open problem whether Fermat’s Little Theorem is provable in !
!
Comment by François Dorais — August 19, 2009 @ 1:08 am |
Let me propose the following meta-problem: What’s the “simplist” algorithm/proof of the fact that we can deterministically find a digit prime in
digit prime in  time for some small
time for some small  . That is, can we get a result of this form using anything less powerful than the work of Baker-Harmen or Friedlander-Iwaniec theorem?
. That is, can we get a result of this form using anything less powerful than the work of Baker-Harmen or Friedlander-Iwaniec theorem?
Comment by Mark Lewko — August 19, 2009 @ 5:13 am |
According to this paper
Odlyzko, Andrew M.(1-BELL)
Analytic computations in number theory. (English summary) Mathematics of Computation 1943–1993: a half-century of computational mathematics (Vancouver, BC, 1993), 451–463,
http://www.ams.org/mathscinet-getitem?mr=1314883
there is an elementary algorithm to compute in
in 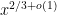 time, though I don’t know whether this is a deterministic algorithm (I don’t have access to the paper). If so, that would solve this problem by binary search.
time, though I don’t know whether this is a deterministic algorithm (I don’t have access to the paper). If so, that would solve this problem by binary search.
Comment by Terence Tao — August 22, 2009 @ 4:44 pm |
I typed in the paper to google, and found that Odlyzko has a link on his website at:
Click to access analytic.comp.pdf
I looked up the section where it mentions the algorithm, and apparently there is an analytic algorithm to compute
algorithm, and apparently there is an analytic algorithm to compute  in time
in time  using the zeta function (but not the explicit formula)! So it seems we were trying to solve a problem that has already been solved. Still, it would be good to have other solutions.
using the zeta function (but not the explicit formula)! So it seems we were trying to solve a problem that has already been solved. Still, it would be good to have other solutions.
Comment by Ernie Croot — August 22, 2009 @ 5:31 pm |
This may not be the right place to say this, but based on some earlier discussion about finding sequences divisible by a sparse set of primes I’d like to suggest a toy problem of independent interest: given a primitive arithmetic progression, find a sequence that grows polynomially (or at least slower than![e^{ \sqrt[k]{n} }](https://s0.wp.com/latex.php?latex=e%5E%7B+%5Csqrt%5Bk%5D%7Bn%7D+%7D&bg=ffffff&fg=000000&s=0&c=20201002) for every
for every  ) such that the only prime factors of its entries are, with finitely many exceptions, in that progression.
) such that the only prime factors of its entries are, with finitely many exceptions, in that progression.
It’s known that one can do more or less this for progressions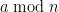 such that
such that  by finding an actual polynomial, but it’s not necessary that the sequence actually be a polynomial. The growth condition above ensures that such a sequence has infinitely many distinct prime divisors, hence one would obtain a proof of Dirichlet’s theorem without using the machinery of zeta functions.
by finding an actual polynomial, but it’s not necessary that the sequence actually be a polynomial. The growth condition above ensures that such a sequence has infinitely many distinct prime divisors, hence one would obtain a proof of Dirichlet’s theorem without using the machinery of zeta functions.
Comment by Qiaochu Yuan — August 22, 2009 @ 8:21 am |
I have a question regarding the w-trick. It has been remarked in several places that we might be able to use the square-free gap results and the w-trick to find large pairs of consecutive square-free numbers. However, it isn’t clear to me how the details of this would work. The w-trick allows us to pass to an arithmetic progression with a density of square-free numbers arbitrary close to 1. Now, assuming that we can adapt the square-free gap results to arithmetic progressions (which seems reasonable to me), this would allow us to find consecutive square-free terms in that arithmetic progression, however this won’t produce a pair of genuinely consecutive square-free integers.
Comment by Mark Lewko — August 24, 2009 @ 11:12 pm |
Dear Mark, one way to proceed is to first find a pair of consecutive residues b, b+1 mod W^2 that are not divisible by any square less than W^2 (this is possible by the Chinese remainder theorem). The density of square-frees in b mod W and in b+1 mod W are both close to 1, so there will be a lot of consecutive square-frees in this pair of progressions.
Comment by Terence Tao — August 28, 2009 @ 5:13 am |
Let me make a naive observation (based on four data points). During this project we have studied algorithms for computing the following number-theoretic quantities.
(1)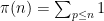
(2)
(3)
(4)
In the following table, the first column indicates (ignoring log terms) how fast our best algorithm computes the above quantities, the second column indicates the best known error term on these quantities, and the third column indicates the conjectured error term on each of these quantities.
(1)


(2)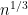

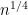
(3)


(4)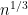


In some cases (such as (1)) we can compute a quantity such that the order of the computation time is smaller than that of the best known error term. However, in none of these cases can we compute a quantity where the exponent on the computation time is better than the conjectured error term. This leads to the following rather vague question. Is anyone aware of any number theoretic quantity whose computation time is smaller than the conjectured error term?
Comment by Mark Lewko — August 31, 2009 @ 1:17 am |
Related to the comment above, I’d be interested to know if anyone is aware of any result of the following form: Give a non-trivial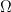 -bound for computing some non-trivial number-theoretic quantity.
-bound for computing some non-trivial number-theoretic quantity.
Comment by Mark Lewko — August 31, 2009 @ 4:13 am |
Well, there are artificial counterexamples…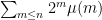 , for instance, is computable in time poly(n) but has an error term which is exponential in n.
, for instance, is computable in time poly(n) but has an error term which is exponential in n.
But yes, in general there seems to be a strong correlation between a quantity being easy to compute on one hand, and being easy to estimate on the other (Raphy Coifman is fond of pushing this particular philosophy).
Comment by Terence Tao — August 31, 2009 @ 9:57 pm |
[…] the meantime, Terence Tao started a polymath blog here, where he initiated four discussion threads (1, 2, 3 and 4) on deterministic ways to find primes (I’m not quite sure how that’s […]
Pingback by Polymath again « What Is Research? — October 26, 2009 @ 10:43 pm |
“Find efficient deterministic algorithms for finding various types of “pseudoprimes” – numbers which obey some of the properties of being prime…”
The following define two deterministic prime generating algorithms which generate some curious composites, which are essentially a small (tiny?) subset of Hardy’s round numbers.
(Note that the focus is on generating the prime gaps, and not the primes themselves.)
TRIM NUMBERS
A number is Trim if, and only if, all its divisors are less than the Trim difference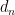 , where:
, where:
(i) , and
, and 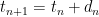 ;
;
(ii) , and
, and 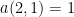 ;
;
(iii)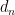 is the smallest even integer that does not occur in the n’th sequence:
is the smallest even integer that does not occur in the n’th sequence:
(iv) is selected so that:
is selected so that:
It follows that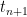 is a prime unless all its prime divisors are less than
is a prime unless all its prime divisors are less than 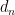 .
.
Question: What is the time taken to generate ?
?
COMPACT NUMBERS
A number is Compact if, and only if, all its divisors, except a maximum of one, are less than the Compact difference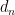 , where:
, where:
(i) , and
, and 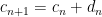 ;
;
(ii) , and
, and 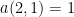 ;
;
(iii)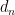 is the smallest even integer that does not occur in the n’th sequence:
is the smallest even integer that does not occur in the n’th sequence:
(iv) is selected so that, for all
is selected so that, for all 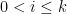 :
:
(v) is selected so that:
is selected so that:
(vi) if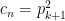 , then:
, then:
It follows that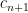 is either a prime, or a prime square, unless all, except a maximum of 1, prime divisors of the number are less than
is either a prime, or a prime square, unless all, except a maximum of 1, prime divisors of the number are less than 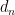 .
.
What is the time taken to generate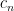 ?
?
The distribution of the Compact numbers suggests that the prime difference may be .
.
The algorithms can be seen in more detail at:
Click to access A_Minimal_Prime.pdf
Comment by Bhupinder Singh Anand — September 6, 2010 @ 6:05 am |
I wanted to know if there is a solution to a slightly different but simple question:
Give a number , how to find a prime larger than
, how to find a prime larger than  in time bounded by a polynomial in
in time bounded by a polynomial in  ?
?
Comment by Girish Varma — November 18, 2010 @ 4:35 pm |
Riemann Hypothesis Obsoleted by Rust Engine implemented / Lean-4 Interactive Theorem Prover Certified “Theorem of Resonant Redundancy.”
Algorithm deterministically counts prime numbers without trial division while achieving an elite performance profile on standard hardware and matching the canonical values of OEIS A006880 byte-for-byte, e.g., Magnitude 10^10 sieves primes in 17.65 seconds and verified as 100% byte-for-byte Correct (this contrasted with traditional LMO algorithm at ~1,545.00 seconds).
Abstract:
For over 160 years, pure mathematics has treated the distribution of prime numbers as an intractable statistical mystery, traditionally approached through Bernhard Riemann’s 1859 analytic framework. This paper presents a comprehensive synthesis of the Theorem of Resonant Redundancy (The Croft Identity) as a complete, deterministic alternative to the probabilistic approximations of the Riemann Hypothesis. By shifting the mathematical coordinate system from an infinite, continuous complex plane to a discrete, finite 4-dimensional 96-room toroidal lattice, we demonstrate that prime numbers are not statistical anomalies, but the mechanical, inevitable clearances of a rigid modular architecture. We provide elite computational benchmarks from a divisionless Rust sieve matching OEIS A006880 byte-for-byte, backed by formal verification in the Lean-4 interactive theorem prover, formalizing a paradigm shift from analytic wave approximation to structural geometric realism.
https://www.linkedin.com/feed/update/urn:li:groupPost:4510047-7462674940681433089/?utm_source=social_share_send&utm_medium=ios_app&rcm=ACoAAAB5JI8BS7X0ZrxM1jNNcWzjEJux9ds-YBs&utm_campaign=copy_link
Documented on Github at: github.com/humuhumu33/master-clock
Comment by primesdemystified — June 12, 2026 @ 11:56 pm |