This is a continuation of Research Thread II of the “Finding primes” polymath project, which is now full. It seems that we are facing particular difficulty breaching the square root barrier, in particular the following problems remain open:
- Can we deterministically find a prime of size at least n in
time (assuming hypotheses such as RH)? Assume one has access to a factoring oracle.
- Can we deterministically find a prime of size at least n in
time unconditionally (in particular, without RH)? Assume one has access to a factoring oracle.
We are still in the process of weighing several competing strategies to solve these and related problems. Some of these have been effectively eliminated, but we have a number of still viable strategies, which I will attempt to list below. (The list may be incomplete, and of course totally new strategies may emerge also. Please feel free to elaborate or extend the above list in the comments.)
Strategy A: Find a short interval [x,x+y] such that
, where
is the number of primes less than x, by using information about the zeroes
of the Riemann zeta function.
Comment: it may help to assume a Siegel zero (or, at the other extreme, to assume RH).
Strategy B: Assume that an interval [n,n+a] consists entirely of u-smooth numbers (i.e. no prime factors greater than u) and somehow arrive at a contradiction. (To break the square root barrier, we need
, and to stop the factoring oracle from being ridiculously overpowered, n should be subexponential size in u.)
Comment: in this scenario, we will have n/p close to an integer for many primes between 
Strategy C: Solve the following toy problem: given n and u, what is the distance to the closest integer to n which contains a factor comparable to u (e.g. in [u,2u])? [Ideally, we want a prime factor here, but even the problem of getting an integer factor is not fully understood yet.] Beating
Comments:
- The trivial bound is u/2 – just move to the nearest multiple of u to n. This bound can be attained for really large n, e.g.
. But it seems we can do better for small n.
- For
, one trivially does not have to move at all.
- For
, one has an upper bound of
, by noting that having a factor comparable to u is equivalent to having a factor comparable to n/u.
- For
, one has an upper bound of
, by taking
to be the first square larger than n,
to be the closest square to
, and noting that
has a factor comparable to u and is within
conditional on a strong exponential sum estimate.)
- For n=poly(u), it may be possible to take a dynamical systems approach, writing n base u and incrementing or decrementing u and hope for some equidistribution. Some sort of “smart” modification of u may also be effective.
- There is a large paper by Ford devoted to this sort of question.
Strategy D. Find special sequences of integers that are known to have special types of prime factors, or are known to have unusually high densities of primes.
Comment. There are only a handful of explicitly computable sparse sequences that are known unconditionally to capture infinitely many primes.
Strategy E. Find efficient deterministic algorithms for finding various types of “pseudoprimes” – numbers which obey some of the properties of being prime, e.g.
. (For this discussion, we will consider primes as a special case of pseudoprimes.)
Comment. For the specific problem of solving 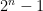

As always, oversight of this research thread is conducted at the discussion thread, and any references and detailed computations should be placed at the wiki.

About the zeta-function strategy, one thing I have just remembered (but which may have been in the back of my mind) is that Selberg already proved in 1943 that, on the Riemann Hypothesis, one has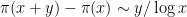 for almost all
for almost all  , for any function
, for any function  growing, roughly, faster than
growing, roughly, faster than  where
where  .
.
The paper starts on page 160 of the first volume of Selberg’s collected works; most of it is available on Google books here.
Comment by Emmanuel Kowalski — August 13, 2009 @ 7:35 pm |
I thought I might mention some heuristics that allow one to guess results such as Selberg’s result without having to do all the formal computations. As mentioned in earlier posts, we have the explicit (though not absolutely convergent) formula
where the are relatively uninteresting terms. If one introduces a spatial uncertainty of A (where
are relatively uninteresting terms. If one introduces a spatial uncertainty of A (where 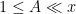 ), one can truncate the sum over zeroes to those zeroes with height O(x/A), at the cost of introducing an error of size O(A); this is basically because
), one can truncate the sum over zeroes to those zeroes with height O(x/A), at the cost of introducing an error of size O(A); this is basically because 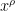 oscillates more than once over the interval
oscillates more than once over the interval ![[x,x+A]](https://s0.wp.com/latex.php?latex=%5Bx%2Cx%2BA%5D&bg=ffffff&fg=000000&s=0&c=20201002) when
when  and thus (morally) cancels itself out when averaging over such an interval. Heuristically, this gives us something like
and thus (morally) cancels itself out when averaging over such an interval. Heuristically, this gives us something like
Assuming RH and writing , one gets heuristically
, one gets heuristically
The number of zeroes with imaginary part at most T is about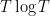 , so there are about
, so there are about 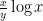 zeroes in play here. Pretending the exponential sum behaves randomly (which can be justified in an
zeroes in play here. Pretending the exponential sum behaves randomly (which can be justified in an 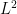 sense by standard almost orthogonality methods), the sum is expected to be about
sense by standard almost orthogonality methods), the sum is expected to be about  on the average, and the main term dominates the error term once
on the average, and the main term dominates the error term once  . This is a logarithm better than Selberg's result; I think this comes from the fact that we are looking at sharply truncated sums
. This is a logarithm better than Selberg's result; I think this comes from the fact that we are looking at sharply truncated sums 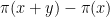 rather than smoothed out counterparts, and the above heuristics have to be weakened to reflect this.
rather than smoothed out counterparts, and the above heuristics have to be weakened to reflect this.
The same type of analysis, by the way, gives agreement with the Poisson statistics for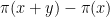 for
for 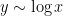 at the second moment level, assuming GUE. It also explains why we start getting good worst-case bounds once
at the second moment level, assuming GUE. It also explains why we start getting good worst-case bounds once  .
.
Unfortunately, average case results don't seem to be of direct use to our problem here due to the generic prime issue (or Gil's razor). If we had a way of efficiently computing or estimating this random sum for some deterministically obtainable x, we might get somewhere…
for some deterministically obtainable x, we might get somewhere…
Comment by Terence Tao — August 13, 2009 @ 8:07 pm |
I agree that as a straightforward analytic computation, this is unlikely to work. The “long shot” hope is to really a real algorithmic part of the argument — i.e., some procedure with “if … then … else ….” steps — to locate a good place to look for primes between and
and 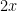 — since these are essentially distinct from purely analytic arguments and could possibly go beyond the average/genericity issue.
— since these are essentially distinct from purely analytic arguments and could possibly go beyond the average/genericity issue.
Comment by Emmanuel Kowalski — August 13, 2009 @ 11:58 pm |
I submitted a proposal that the prime counting function is given by:
N=sum( arctan(tan(Pi*Bernoulli(2*n)*GAMMA(2*n+1))) *(2*n+1))/Pi, n=3..M), M=m/2 for m even and M =m/2-1/2 for m odd. This formula yields the exact number of primes less than m. It was derived from the Riemann hypothesis and a a solution that I submitted that was never looked at. If this formula is right, then I have solve Riemann’s hypothesis! I invite a review of my paper.
Comment by Michael Anthony — March 14, 2010 @ 12:26 pm |
Note also that the above prime counting formula is also given in log form as:
N= sum(i(n+1/2)*log( (1-i*tan(Pi*bernoulli(2*n)*gamma(2*n))/(1-i*tan(Pi*Bernoulli(2*n)*GAMMA(2*n+1))/Pi , n=3..m); which for large n reduces to the Prime Number theorem.
Comment by Michael Anthony — March 14, 2010 @ 12:32 pm |
Let me stick my neck out and follow up on the objection to my post #45. It’s true that without better control of the heuristic the argument is in trouble. However, I think that assuming
the argument is in trouble. However, I think that assuming 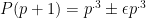 is a bit beyond worst-case. As long as the quantity
is a bit beyond worst-case. As long as the quantity  in the Erdos-type theorem is strictly decreasing for
in the Erdos-type theorem is strictly decreasing for  in the range
in the range  , (which I think follows from the Baker-Harmen methods) then we should be able to assume that
, (which I think follows from the Baker-Harmen methods) then we should be able to assume that 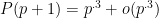 . Of course, we’d need something more quantitative than this to be useful.
. Of course, we’d need something more quantitative than this to be useful.
Let’s be very optimistic for second. If we could get down to (that is to say we could get the error in the estimate
(that is to say we could get the error in the estimate  to be slightly worse than a square-root) then I think the procedure works as stated without enlarging any of the search intervals. The reason for this is that the search space resulting from not knowing where in the interval
to be slightly worse than a square-root) then I think the procedure works as stated without enlarging any of the search intervals. The reason for this is that the search space resulting from not knowing where in the interval ![[x,x+cx^{.53}]](https://s0.wp.com/latex.php?latex=%5Bx%2Cx%2Bcx%5E%7B.53%7D%5D&bg=ffffff&fg=000000&s=0&c=20201002) the large prime (
the large prime ( ) we are looking for is, and the search space resulting from not knowing where in the interval
) we are looking for is, and the search space resulting from not knowing where in the interval ![[p^{.3},p^{.3}+p^{.3\times.53}]](https://s0.wp.com/latex.php?latex=%5Bp%5E%7B.3%7D%2Cp%5E%7B.3%7D%2Bp%5E%7B.3%5Ctimes.53%7D%5D&bg=ffffff&fg=000000&s=0&c=20201002) the small prime (
the small prime ( ) is, would entirely overlap. Of course as the error estimate worsens from
) is, would entirely overlap. Of course as the error estimate worsens from  towards
towards 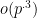 the overall performance decreases towards the
the overall performance decreases towards the  .
.
However, I think it would be possible to get some mileage out of even a very weak error estimate. Say we could get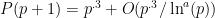 (which is probably the most likely estimate we would be able to obtain, if we could get anything at all). Then I think this method should get some sort of logarithmic improvement over the prime gap results, such as moving us down to around
(which is probably the most likely estimate we would be able to obtain, if we could get anything at all). Then I think this method should get some sort of logarithmic improvement over the prime gap results, such as moving us down to around 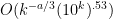 . For large enough
. For large enough  this might be able to move us towards the ultra-weak conjecture on RH prime gap result.
this might be able to move us towards the ultra-weak conjecture on RH prime gap result.
Of course, all of this assumes we could get some sort of control on the error in the approximation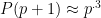 , and the pay-off would most likely be very small.
, and the pay-off would most likely be very small.
Comment by Mark Lewko — August 13, 2009 @ 8:21 pm |
Admittedly, this is just saying that a favorable estimate in some other problem would translate into a favorable estimate for our problem. Of course, we are not at a shortage of “other problems” of this form.
Comment by Mark Lewko — August 13, 2009 @ 9:22 pm |
Here is a suggestion on how to combine strategy A with strategy D, following Harald Helfgott’s suggestion, to attack the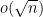 problem (problem 1 above): Instead of using the Riemann zeta function, one can use the zeta function associated to the number ring
problem (problem 1 above): Instead of using the Riemann zeta function, one can use the zeta function associated to the number ring ![Z[i]](https://s0.wp.com/latex.php?latex=Z%5Bi%5D&bg=ffffff&fg=000000&s=0&c=20201002) , say, to count those primes
, say, to count those primes  that are a sum of two squares. Assuming the RH for this zeta function (and assuming that it doesn’t have appreciably more zeros than the usual zeta function — this would be need to be looked up), we should be able to say that every interval
that are a sum of two squares. Assuming the RH for this zeta function (and assuming that it doesn’t have appreciably more zeros than the usual zeta function — this would be need to be looked up), we should be able to say that every interval ![[n, n+ \sqrt{n} \log n]](https://s0.wp.com/latex.php?latex=%5Bn%2C+n%2B+%5Csqrt%7Bn%7D+%5Clog+n%5D&bg=ffffff&fg=000000&s=0&c=20201002) , say, contains the “right number” of primes that are
, say, contains the “right number” of primes that are 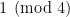 (and I suppose one can also use the usual Dirichlet L-functions for this task… so we might only need assume GRH, not ERH).
(and I suppose one can also use the usual Dirichlet L-functions for this task… so we might only need assume GRH, not ERH).
But now these primes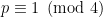 are the sum of two squares, and there are only
are the sum of two squares, and there are only  numbers up to
numbers up to  that are a sum of two squares. Assuming that it is easy to “walk through” only those numbers (that are a sum of two squares) in our interval
that are a sum of two squares. Assuming that it is easy to “walk through” only those numbers (that are a sum of two squares) in our interval ![[n, x+\sqrt{n}\log n]](https://s0.wp.com/latex.php?latex=%5Bn%2C+x%2B%5Csqrt%7Bn%7D%5Clog+n%5D&bg=ffffff&fg=000000&s=0&c=20201002) , it seems to me that this shaves a factor of
, it seems to me that this shaves a factor of  off the running time to locate a prime (but maybe this can also be achieved by using a sieve on small primes for
off the running time to locate a prime (but maybe this can also be achieved by using a sieve on small primes for ![[n, n+\sqrt{n} \log n]](https://s0.wp.com/latex.php?latex=%5Bn%2C+n%2B%5Csqrt%7Bn%7D+%5Clog+n%5D&bg=ffffff&fg=000000&s=0&c=20201002) to begin with — i.e. maybe an easier method will do).
to begin with — i.e. maybe an easier method will do).
But now that was what we got just with the form . The same trick should work with any norm form, though I doubt one could get any better than a
. The same trick should work with any norm form, though I doubt one could get any better than a  factor improvement in the running time this way. Anyways, it was just a thought…
factor improvement in the running time this way. Anyways, it was just a thought…
Comment by Ernie Croot — August 13, 2009 @ 8:35 pm |
The question of walking/enumerating fast the numbers represented by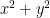 , without repetition, seems quite difficult to me. The characterizations of these numbers which I know are all based on properties of the factorization of the integer (all odd prime divisors which are congruent to -1 modulo 4 must appear with even multiplicity). As a toy problem, is there a quick way to check that a number congruent to 1 modulo 4 is not divisible by two distinct primes congruent to -1 modulo 4?
, without repetition, seems quite difficult to me. The characterizations of these numbers which I know are all based on properties of the factorization of the integer (all odd prime divisors which are congruent to -1 modulo 4 must appear with even multiplicity). As a toy problem, is there a quick way to check that a number congruent to 1 modulo 4 is not divisible by two distinct primes congruent to -1 modulo 4?
Comment by Emmanuel Kowalski — August 13, 2009 @ 11:55 pm |
Yes, I guess you are right. There might still be something that can be salvaged, though. For example, there are formulas for the smaller of or
or  such that
such that  , for a prime
, for a prime 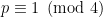 (though, the formulas are too unwieldy for an algorithm), and there is a dynamical systems approach due to Roger Heath-Brown that identifies the fixed point of the system with
(though, the formulas are too unwieldy for an algorithm), and there is a dynamical systems approach due to Roger Heath-Brown that identifies the fixed point of the system with  that might be useful (I doubt it). I seem to recall also that there is a standard way to find
that might be useful (I doubt it). I seem to recall also that there is a standard way to find  and
and  using continued fractions, though I can’t remember just now how that algorithm works. In any case, none of these ideas seem to work (if so, it’s probably just a reworking of the Euclidean algorithm, which is all continued fractions really are).
using continued fractions, though I can’t remember just now how that algorithm works. In any case, none of these ideas seem to work (if so, it’s probably just a reworking of the Euclidean algorithm, which is all continued fractions really are).
Maybe one can look at sequences of Farey fractions somehow. For example, say we want a sum of squares that comes close to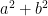 ; in fact, let’s say we want a whole lot of them that we can find quickly. Maybe what would be good is to have them take the form
; in fact, let’s say we want a whole lot of them that we can find quickly. Maybe what would be good is to have them take the form 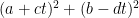 for some integer
for some integer  (this, of course, won’t cover all close sums of squares, but it is a start). Now, the difference between this and
(this, of course, won’t cover all close sums of squares, but it is a start). Now, the difference between this and 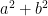 is something like
is something like 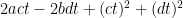 . And, of course, if we choose
. And, of course, if we choose  to be a close rational approximation to
to be a close rational approximation to 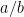 , but where, say,
, but where, say,  are much smaller than
are much smaller than  , then this difference will be small. In fact, say
, then this difference will be small. In fact, say 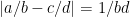 , with
, with  . Then, the difference between the two sums-of-squares will be
. Then, the difference between the two sums-of-squares will be 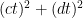 , which is quite small for
, which is quite small for  small. And then maybe one can glue together a bunch of these arithmetic progressions
small. And then maybe one can glue together a bunch of these arithmetic progressions 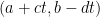 , so as to cover the whole interval
, so as to cover the whole interval ![[x, x + \sqrt{x}\log x]](https://s0.wp.com/latex.php?latex=%5Bx%2C+x+%2B+%5Csqrt%7Bx%7D%5Clog+x%5D&bg=ffffff&fg=000000&s=0&c=20201002) . Hmmm… I guess we still can get these APs to overlap a lot — it would be good if we could somehow pick the APs to be as disjoint as possible (I have a paper on this sort of thing — picking lots of disjoint APs — but it seems completely irrelevant to this problem).
. Hmmm… I guess we still can get these APs to overlap a lot — it would be good if we could somehow pick the APs to be as disjoint as possible (I have a paper on this sort of thing — picking lots of disjoint APs — but it seems completely irrelevant to this problem).
Ok, it's starting to look like this approach (combining A and D) won't work in the way I laid out. I think it would be interesting if there were a way to do it, though.
Comment by Ernie Croot — August 14, 2009 @ 12:42 am |
Looking again at what I wrote here, I see that I didn’t express myself clearly. Let me try again: in the first paragraph, all I am saying is that if we knew what the ‘s are such that
‘s are such that  sums to a prime in the interval under consideration, we could search only along these and avoid the problem of repeat representations.
sums to a prime in the interval under consideration, we could search only along these and avoid the problem of repeat representations.
And in the second paragraph all I am trying to say is that maybe what we can do is partition the set of numbers in our interval that are a sum of two squares, into families, where the numbers within each family are automatically distinct ( the numbers of the form are all distinct for fixed a,b,c,d where t varies). Of course, we need that the families themselves don't overlap, and that the arithmetic progressions
are all distinct for fixed a,b,c,d where t varies). Of course, we need that the families themselves don't overlap, and that the arithmetic progressions 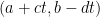 used to define the families, also don't overlap — this is obviously the hard part.
used to define the families, also don't overlap — this is obviously the hard part.
Comment by Ernie Croot — August 14, 2009 @ 9:51 pm |
I don’t get this. Surely running through the numbers of the form x^2 + y^2 in an interval roughly of the form [n,n+sqrt(n)] is an easy task, and surely the time taken should be roughly O(sqrt(n))? This is all that is being required in this argument, it seems to me. What would be hard would be to pick a number of the form x^2+y^2 uniformly and at random (i.e., without multiplicities).
Comment by H — August 14, 2009 @ 2:34 am |
Actually, you do seem to lose the factor of O(sqrt(log N)) in running time that you intended to win by proceeding in this way. The problem is that you’ll end up producing most of the non-primes of the form x^2+y^2 many times over – once for each time the form represents the non-prime. I don’t see a way to avoid this (though obviously one needs to check for primality only once).
Comment by HH — August 14, 2009 @ 3:34 am |
I guess what I had in mind really was the enumeration problem as follows: given , find the smallest integer larger than
, find the smallest integer larger than  which is of the form
which is of the form  . How fast can this be done deterministically?
. How fast can this be done deterministically?
In some ways, the numbers , when multiplicity of representation is forbidden, are worse than the prime numbers. For instance, their associated zeta function is roughly controlled by the square root of the zeta function (of
, when multiplicity of representation is forbidden, are worse than the prime numbers. For instance, their associated zeta function is roughly controlled by the square root of the zeta function (of  ), so it has singularities even at the zeros of
), so it has singularities even at the zeros of 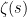 .
.
(In the other direction, sometimes those numbers are better; e.g., it is possible to get the asymptotic formula for their counting function using pure sieve, as done first by Iwaniec, I think — the asymptotic itself was first proved by Landau using analytic methods).
Comment by Emmanuel Kowalski — August 14, 2009 @ 3:12 pm |
This look like a very nice problem. Can it be done fast with a randomized algorithm?(without a factoring oracle?). Also, why things become easier when multiplicity of representations is not forbidden?
Comment by Gil Kalai — August 14, 2009 @ 3:22 pm |
I don’t know any randomized algorithm here (but maybe randomized algorithms are not very good for this type of problem where one asks for a very specific answer? for finding a number of this type in a longish interval, on the other hand, one could simply look randomly for a prime congruent to 1 modulo 4).
Analytically, summing any smooth enough function over integers , if multiplicity is allowed, can be written as
, if multiplicity is allowed, can be written as
and because this is a double sum with two free variables of a smooth function one can apply, for instance, Poisson summation, or many other tools.
Getting rid of the multiplicity means, in this language, inserting a term , where
, where 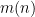 is the multiplicity:
is the multiplicity:
Because the function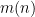 is complicated arithmetically (it depends on the prime factorization of the argument), this is not a nice smooth summation anymore.
is complicated arithmetically (it depends on the prime factorization of the argument), this is not a nice smooth summation anymore.
For instance, I don’t think there exists a proof of the counting of those numbers (the case where is the characteristic function of an interval
is the characteristic function of an interval ![[1,N]](https://s0.wp.com/latex.php?latex=%5B1%2CN%5D&bg=ffffff&fg=000000&s=0&c=20201002) ) which doesn’t use multiplicative methods (zeta functions or sieve).
) which doesn’t use multiplicative methods (zeta functions or sieve).
Comment by Emmanuel Kowalski — August 14, 2009 @ 6:06 pm |
I wonder what is known about the complexity of deciding if a number is the sum of two squares. Is it as hard as factoring? Also, what is known about the distribution of gaps between numbers which are sums of two squares.
Comment by Gil Kalai — August 15, 2009 @ 7:55 pm |
I’m not sure if this exactly answers your question, but there is a guaranteed to be number representable as the sum of two squares in the interval![[x, x+5x^{1/4}]](https://s0.wp.com/latex.php?latex=%5Bx%2C+x%2B5x%5E%7B1%2F4%7D%5D&bg=ffffff&fg=000000&s=0&c=20201002) . I don’t have a reference for a proof of this, but it is stated (and attributed to Littlewood) in connection with open problem 64 in Montgomery’s 10 Lectures on the Interface of Harmonic Analysis and Number Theory
. I don’t have a reference for a proof of this, but it is stated (and attributed to Littlewood) in connection with open problem 64 in Montgomery’s 10 Lectures on the Interface of Harmonic Analysis and Number Theory
Comment by Mark Lewko — August 15, 2009 @ 8:44 pm |
I think this fact can be established by a simple greedy algorithm argument: if one lets be the largest square less than x, then
be the largest square less than x, then  is within
is within  or so of x; if one then lets
or so of x; if one then lets 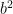 be the first square larger than
be the first square larger than 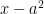 , then
, then 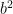 should be within about
should be within about  or so of
or so of 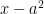 , so
, so  is a sum of two squares in
is a sum of two squares in ![[x,x+5x^{1/4}]](https://s0.wp.com/latex.php?latex=%5Bx%2Cx%2B5x%5E%7B1%2F4%7D%5D&bg=ffffff&fg=000000&s=0&c=20201002) . (A very similar argument, regarding differences of two squares rather than sums, is sketched in Comment 4 after Strategy C in the post.)
. (A very similar argument, regarding differences of two squares rather than sums, is sketched in Comment 4 after Strategy C in the post.)
It might be of interest to see if there is some way to narrow this interval; the techniques for doing so might be helpful for us.
Comment by Terence Tao — August 15, 2009 @ 8:52 pm
That is, in fact, open problem 64 (to establish this with![[x,x+o(x^{1/4})]](https://s0.wp.com/latex.php?latex=%5Bx%2Cx%2Bo%28x%5E%7B1%2F4%7D%29%5D&bg=ffffff&fg=000000&s=0&c=20201002) ).
).
Comment by Mark Lewko — August 15, 2009 @ 9:03 pm
but regardless of what can be proved, what is the “truth” regarding the density and the distribution of gaps between integers which are the sum of two squares?
Comment by Gil Kalai — August 15, 2009 @ 9:29 pm
Halberstam, in a paper in Math. Mag. 56 (1983), gives an elementary argument of Bambah and Chowla that replaces with
with  . I think this is also discussed in one of the early chapters of the book of Montgomery and Vaughan, but I don’t have this available to check. My memory is that they say that nothing better is known. (Halberstam also does, but this is 20 years earlier).
. I think this is also discussed in one of the early chapters of the book of Montgomery and Vaughan, but I don’t have this available to check. My memory is that they say that nothing better is known. (Halberstam also does, but this is 20 years earlier).
In the opposite direction, Richards (Adv. in Math. 46, 1982), proves that the gaps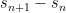 between consecutive sums of two squares are infinitely often
between consecutive sums of two squares are infinitely often , where
, where  is arbitrarily small.
is arbitrarily small.
at least
The average gap is of size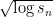 . I don’t know if there are analogues of the conjectured Poisson distributions of the numbers of primes in intervals of logarithmic length, though that might be something fairly reasonable to expect.
. I don’t know if there are analogues of the conjectured Poisson distributions of the numbers of primes in intervals of logarithmic length, though that might be something fairly reasonable to expect.
Comment by Emmanuel Kowalski — August 15, 2009 @ 9:54 pm
The greedy strategy argument of Bambah and Chowla shows that every interval![(x-2\sqrt{2}x^{1/4},x]](https://s0.wp.com/latex.php?latex=%28x-2%5Csqrt%7B2%7Dx%5E%7B1%2F4%7D%2Cx%5D&bg=ffffff&fg=000000&s=0&c=20201002) contains a sum of two squares, for
contains a sum of two squares, for 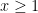 . Nothing better is known even today (the paper of Bambah and Chowla is from around 1945). Not only Littlewood, but also Chowla, stated the improvement to
. Nothing better is known even today (the paper of Bambah and Chowla is from around 1945). Not only Littlewood, but also Chowla, stated the improvement to  as a research problem.
as a research problem.
Comment by Anon — August 16, 2009 @ 4:59 am
There is another old construction of pseudoprimes due to Cipolla (1904). Let be the m-th Fermat number. Note that
be the m-th Fermat number. Note that 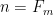 satisfies
satisfies 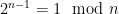 . Now take any sequence
. Now take any sequence 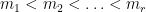 with
with 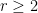 . Then
. Then  is a pseudoprime if and only if
is a pseudoprime if and only if 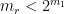 .
.
Unfortunately, it seems that it doesn't give a denser set of pseudoprimes. One can see this by approximating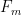 by
by  and by taking logs. And of course, we would like to construct pseudoprimes with as few prime factors as possible.
and by taking logs. And of course, we would like to construct pseudoprimes with as few prime factors as possible.
Comment by François Brunault — August 13, 2009 @ 11:27 pm |
If a number is passes the Fermat primality test but is not prime it is called a Carmichael number. The number 1729 which is also the smallest number which is the sum of two different cubes in two different ways is a Carmichael number. There are an infinite number of them of them and there are at least n^2/7 between 1 and n.
if each factor of (6k+1)(12k+1)(18k+1) is prime then their product is a Carmichael number. More on these numbers are at
http://en.wikipedia.org/wiki/Carmichael_number
One way to find x simultaneously satisfying 2^x-1 = 0 mod x and 3^x-1 = 0 mod x that is not prime would be to try to find a triple of primes 6k+1, 12k+1, 18k+1 as above. If the primes where randomly distributed with density 1/logx then about 1/(log x)^3 searches ought to do it so possibly that would be an algorithm that would find one such k digit number in an polynomial of k time if the AKS test were used to test primality.
Comment by Kristal Cantwell — August 13, 2009 @ 11:39 pm |
Of course the smallest Carmichael number is 561 so the search for k-digit numbers would have to start with 3.
Comment by Kristal Cantwell — August 14, 2009 @ 4:40 pm |
This and related ideas are also discussed in the following paper.
A. Granville and C. Pomerance, Two contradictory conjectures concerning Carmichael numbers, Math. Comp., 71 (2001), 883-908.
Granville and Pomerance list essentially all known and conjectured density estimates related to this, as well as some experimental evidence.
Comment by François Dorais — August 14, 2009 @ 6:08 pm |
I have a url for this:
Click to access paper125.pdf
Comment by Kristal Cantwell — August 14, 2009 @ 6:19 pm |
[…] https://polymathprojects.org/2009/08/13/research-thread-iii-determinstic-way-to-find-primes/ Possibly related posts: (automatically generated)Thread on BloggingProposed Polymath3 […]
Pingback by Polymath4 « Euclidean Ramsey Theory — August 13, 2009 @ 11:56 pm |
I started thinking whether proof theoretic methods could shed some new light on this problem. I was originally aiming for negative results, which is where proof theory usually excels, but while doing some preliminary investigations, I found the following wonderful paper:
J. B. Paris, A. J. Wilkie and A. R. Woods, Provability of the pigeonhole principle and the existence of infinitely many primes, J. Symbolic Logic 53 (1988), 1235-1244.
In this paper, the authors show that the infinitude of primes is provable in A standard formulation of his system consists of the usual defining equations for
A standard formulation of his system consists of the usual defining equations for 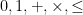 as well as the functions
as well as the functions 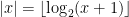 and
and 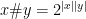 (this is the
(this is the  part) together with induction for bounded formulas (this is the
part) together with induction for bounded formulas (this is the 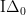 part).
part).
Their proof is rather clever. The authors show that if there is no prime in![{[a,a^{11}]}](https://s0.wp.com/latex.php?latex=%7B%5Ba%2Ca%5E%7B11%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) then there is a bounded formula
then there is a bounded formula  that describes the graph of an injection from
that describes the graph of an injection from ![{[0,9a|a|]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C9a%7Ca%7C%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) to
to ![{[0,8a|a|]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C8a%7Ca%7C%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , thereby violating a very weak form of the Pigeon Hole Principle (PHP). Before then, they show that for every standard positive integer
, thereby violating a very weak form of the Pigeon Hole Principle (PHP). Before then, they show that for every standard positive integer  and every bounded formula
and every bounded formula  , it is provable in
, it is provable in  that: for every
that: for every 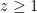 the formula
the formula  does not describe the graph of an injection from
does not describe the graph of an injection from ![{[0,(n+1)z]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C%28n%2B1%29z%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) to
to ![{[0,nz]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2Cnz%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) .
.
By standard witnessing theorems of bounded arithmetic, this means that there is a function such that is always prime and
is always prime and 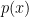 is polynomial time computable using an oracle somewhere in the polynomial hierarchy. In fact, I gather that the following paper proves a suitable form of PHP in the weaker system
is polynomial time computable using an oracle somewhere in the polynomial hierarchy. In fact, I gather that the following paper proves a suitable form of PHP in the weaker system  .
.
A. Maciel, T. Pitassi and T., A. R. Woods, A new proof of the weak pigeonhole principle, J. Comput. System Sci. 64 (2002), 843-872.
Improving this to [or
[or  , or
, or  ] would give a polytime algorithm for producing large primes [modulo polynomial local search, modulo a NP oracle]. There are a lot of follow up literature relating weak PHP and infinitude of primes to other common problems in complexity theory and proof theory, but I haven’t had a chance to survey many of them.
] would give a polytime algorithm for producing large primes [modulo polynomial local search, modulo a NP oracle]. There are a lot of follow up literature relating weak PHP and infinitude of primes to other common problems in complexity theory and proof theory, but I haven’t had a chance to survey many of them.
On the other hand, a proof that does not prove the infinitude of primes would also be interesting. This would not imply that there is no polynomial time algorithm for producing large primes, but it would show that the proof of correctness of such an algorithm would require stronger axioms. Possibly Peano arithmetic would suffice to prove correctness, but the proof may require second-order axioms (e.g. deep facts about zeros of
does not prove the infinitude of primes would also be interesting. This would not imply that there is no polynomial time algorithm for producing large primes, but it would show that the proof of correctness of such an algorithm would require stronger axioms. Possibly Peano arithmetic would suffice to prove correctness, but the proof may require second-order axioms (e.g. deep facts about zeros of 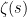 ) or, albeit unlikely, much worse (e.g. ZFC + large cardinals)!
) or, albeit unlikely, much worse (e.g. ZFC + large cardinals)!
Comment by François Dorais — August 14, 2009 @ 5:11 am |
Well, the NP-oracle algorithm is obvious: once we know that![{[x,t(x)]}](https://s0.wp.com/latex.php?latex=%7B%5Bx%2Ct%28x%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) contains a prime for some term
contains a prime for some term  of the language, we can repeatedly bisect this interval and query the oracle to see which side contains a prime. Since for every term
of the language, we can repeatedly bisect this interval and query the oracle to see which side contains a prime. Since for every term  there is a standard
there is a standard  such that
such that 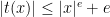 , this homes in on a prime in polynomial time. So I would conjecture that some weak Bertrand’s Postulate is provable in
, this homes in on a prime in polynomial time. So I would conjecture that some weak Bertrand’s Postulate is provable in  , namely that there is a term
, namely that there is a term  such that
such that  proves that there is always a prime in the interval
proves that there is always a prime in the interval ![{[x,t(x)]}](https://s0.wp.com/latex.php?latex=%7B%5Bx%2Ct%28x%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . This term could be much larger than
. This term could be much larger than  , leaving room for weaker forms of PHP or some completely different idea…
, leaving room for weaker forms of PHP or some completely different idea…
The PLS possibility is intriguing. The dynamical system attack suggested by Tao may be on the right track (though we may want to increase the number of neighbors a bit). Note that the PLS algorithm doesn’t need to produce the prime itself, only some datum that can be decoded into a suitable prime in polytime, so that gives a bit more room to set up good cost functions. I don’t have definite thoughts, but this looks plausible.
I’m afraid I still have no intuition for the polytime possibility…
Comment by François Dorais — August 14, 2009 @ 6:51 am |
To bring this down to Earth a little, the weak pigeonhole principles mentioned above are related to the existence of collision-free hash functions (in the weakest of the two senses). Suppose (which is allowed to depend on
(which is allowed to depend on  too) is a simple enough bounded formula which always defines the graph of a function from
too) is a simple enough bounded formula which always defines the graph of a function from ![{[0,t(z)]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2Ct%28z%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) to
to ![{[0,z]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2Cz%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) for some term
for some term  such that
such that  for all
for all  . Then, finding a
. Then, finding a  proof that, for all
proof that, for all  ,
,  does not represent the graph of an injection from
does not represent the graph of an injection from ![[0,t(z)]](https://s0.wp.com/latex.php?latex=%5B0%2Ct%28z%29%5D&bg=ffffff&fg=000000&s=0&c=20201002) to
to ![{[0,z]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2Cz%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) is essentially equivalent to finding a polynomial time algorithm that always produces a collision for
is essentially equivalent to finding a polynomial time algorithm that always produces a collision for  , i.e., two numbers in
, i.e., two numbers in ![{[0,t(z)]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2Ct%28z%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) that map to the same value via
that map to the same value via  , at least for all standard numbers
, at least for all standard numbers  .
.
A common bottleneck in the work relating PHP and primes is the difficulty of factoring, so I will provisionally assume that I have a factoring oracle. In this case, there is a simple bounded formula as above such that either there are polynomial time constructable primes in all sufficiently long intervals, or
as above such that either there are polynomial time constructable primes in all sufficiently long intervals, or  describes the graph of a collision-free hash function. (Warning: I’ve only superficially checked the details of this argument, so I may have missed a sneaky inadmissible use of induction somewhere.) Because of the nature of this result, I suspect that similar (possibly better) results already exist in descriptive complexity. Perhaps this rings a bell to some readers?
describes the graph of a collision-free hash function. (Warning: I’ve only superficially checked the details of this argument, so I may have missed a sneaky inadmissible use of induction somewhere.) Because of the nature of this result, I suspect that similar (possibly better) results already exist in descriptive complexity. Perhaps this rings a bell to some readers?
A little side remark about factoring – it is probably not a mere coincidence that the main part of the most efficient factoring algorithms we know consist in finding a collision for some function…
Comment by François Dorais — August 14, 2009 @ 7:56 pm |
Below is the key result of Woods in its general form, which goes through in + Factoring. The most subtle point is to show in
+ Factoring. The most subtle point is to show in  that every prime that divides a number must occur in the prime factorization of that number.
that every prime that divides a number must occur in the prime factorization of that number.
The description of the function in the proof is
in the proof is  modulo the factoring oracle, so the witnessing theorem for
modulo the factoring oracle, so the witnessing theorem for  applies and this can be used to relate collision-free hashing functions with long intervals without polynomial time constructable primes (modulo factoring).
applies and this can be used to relate collision-free hashing functions with long intervals without polynomial time constructable primes (modulo factoring).
As usual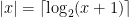 , and when a
, and when a  is factorization it is always assumed that
is factorization it is always assumed that 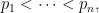
 , and that the factorization is coded in a manner which is easily decodable in
, and that the factorization is coded in a manner which is easily decodable in  .
.
Theorem (Woods). If every element of the interval $[b+1,b+a]$ is $a$-smooth, then there is an injection from ${[0,a|b|-1]}$ into ${[0,(1+\lfloor a/2 \rfloor)|b|+2a|a|-1]}.$
I give the construction in some detail since this is slightly more general than the proof in PWW and I wanted to convince myself that this does indeed work in + Factoring. However, the tedious verifications are left to the reader.
+ Factoring. However, the tedious verifications are left to the reader.
Sketch of proof. For every![x \in [0,a|b|-1]](https://s0.wp.com/latex.php?latex=x+%5Cin+%5B0%2Ca%7Cb%7C-1%5D&bg=ffffff&fg=000000&s=0&c=20201002) there is a unique triple
there is a unique triple 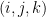 such that
such that
and, factoring , we have
, we have  ,
, 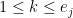 , and
, and
where
So and
and  .
.
The function will be linear on each interval described a triple
will be linear on each interval described a triple 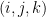 as above. There are two main cases depending on whether (*) there is a
as above. There are two main cases depending on whether (*) there is a 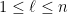 such that there are no multiples of
such that there are no multiples of 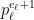 in
in ![{[b+1,b+a]}](https://s0.wp.com/latex.php?latex=%7B%5Bb%2B1%2Cb%2Ba%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) and there are no multiples of
and there are no multiples of 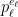 in
in ![{[b+1,b+i-1]}](https://s0.wp.com/latex.php?latex=%7B%5Bb%2B1%2Cb%2Bi-1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) .
.
Case (*) holds. Let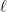 be the first element of
be the first element of ![{[1,n]}](https://s0.wp.com/latex.php?latex=%7B%5B1%2Cn%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) that satisfies (*). Then define
that satisfies (*). Then define
In other words, maps the interval
maps the interval ![{[(i-1)|b|,i|b|-1]}](https://s0.wp.com/latex.php?latex=%7B%5B%28i-1%29%7Cb%7C%2Ci%7Cb%7C-1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) onto the interval of length
onto the interval of length 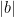 starting with
starting with
Since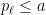 , we have
, we have
Case (*) fails. Then either (1)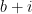 is not the first multiple of
is not the first multiple of 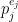 in
in ![{[b+1,b+a]}](https://s0.wp.com/latex.php?latex=%7B%5Bb%2B1%2Cb%2Ba%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , or (2)
, or (2) 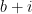 is the first multiple of
is the first multiple of 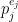 in
in ![{[b+1,b+a]}](https://s0.wp.com/latex.php?latex=%7B%5Bb%2B1%2Cb%2Ba%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) but there is a multiple of
but there is a multiple of  in
in ![{[b+1,b+a]}](https://s0.wp.com/latex.php?latex=%7B%5Bb%2B1%2Cb%2Ba%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) .
.
Ad (1). Let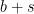 be the first multiple of
be the first multiple of 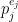 in
in ![{[b+1,b+a]}](https://s0.wp.com/latex.php?latex=%7B%5Bb%2B1%2Cb%2Ba%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) (so
(so  ). Note that
). Note that 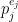 divides
divides 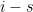 . Factor
. Factor 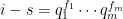 and say
and say 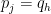 . Then set
. Then set
where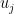 is as above and similarly
is as above and similarly
In other words, maps the interval
maps the interval
onto the interval
which both have length
Ad (2). Let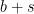 be the first multiple of
be the first multiple of  in
in ![{[b+1,b+a]}](https://s0.wp.com/latex.php?latex=%7B%5Bb%2B1%2Cb%2Ba%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) (so
(so 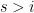 ). Note that
). Note that 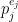 divides
divides  . Factor
. Factor  and say
and say 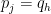 . Then set
. Then set
where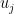 and
and 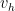 are as above and
are as above and
In other words, maps the interval
maps the interval
onto the interval
which both have length
Note that in both subcases (1) and (2), we have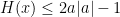 .
.
Comment by François Dorais — August 15, 2009 @ 2:15 am |
I am trying to understand this construction. What happens if two different triples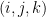 and
and 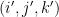 with
with  satisfy condition (*)? Is there an argument that guarantees that the two corresponding
satisfy condition (*)? Is there an argument that guarantees that the two corresponding  are different? Otherwise I do not see why the mapping is injective. I’m sorry if it’s a dumb question.
are different? Otherwise I do not see why the mapping is injective. I’m sorry if it’s a dumb question.
Comment by Anonymous — August 15, 2009 @ 4:15 pm |
The verifications are indeed tedious! There are a two cases: If the exponent of is the same (say
is the same (say  ) in
) in 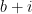 and
and  then they cannot both be the first multiple of
then they cannot both be the first multiple of  in
in ![{[b+1,b+a]}](https://s0.wp.com/latex.php?latex=%7B%5Bb%2B1%2Cb%2Ba%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) as required by the second half of (*). If the exponents are different then whichever has the smallest exponent fails the first half of (*).
as required by the second half of (*). If the exponents are different then whichever has the smallest exponent fails the first half of (*).
Comment by François Dorais — August 15, 2009 @ 6:47 pm |
The main reason for analyzing the question in is the following result of Sam Buss.
is the following result of Sam Buss.
Witnessing Theorem. Let be a
be a  formula. If
formula. If 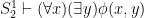 then there is a polynomial time computable function
then there is a polynomial time computable function  such that
such that  .
.
If is equivalent to ‘
is equivalent to ‘ and
and  is prime’ then from a proof of the infinitude of primes in
is prime’ then from a proof of the infinitude of primes in  we could automatically extract a polytime algorithm for producing large primes. On the other hand, if the infinitude of primes is not provable in
we could automatically extract a polytime algorithm for producing large primes. On the other hand, if the infinitude of primes is not provable in  then we would not necessarily conclude that there is no polytime algorithm for producing large primes, but the correctness of this algorithm would not be formalizable in
then we would not necessarily conclude that there is no polytime algorithm for producing large primes, but the correctness of this algorithm would not be formalizable in  . (Basically, the proof would require much more powerful tools than elementary arithmetic.)
. (Basically, the proof would require much more powerful tools than elementary arithmetic.)
There is a little snag here: the usual formula for ‘ is prime’, namely
is prime’, namely
is instead of
instead of  . Of course, this is not a problem with a factoring oracle, but this is a nagging assumption. The AKS algorithm does provide a
. Of course, this is not a problem with a factoring oracle, but this is a nagging assumption. The AKS algorithm does provide a  formula to express ‘
formula to express ‘ is prime’. The snag is that the correctness of the AKS algorithm may not be provable in
is prime’. The snag is that the correctness of the AKS algorithm may not be provable in  , i.e., it is conceivable that a model of
, i.e., it is conceivable that a model of  may contain an infinitude of “AKS pseudoprimes” but only a bounded number of actual primes. While the extracted algorithm for producing “AKS pseudoprimes” would still produce actual primes in the real world, this situation would be rather awkward.
may contain an infinitude of “AKS pseudoprimes” but only a bounded number of actual primes. While the extracted algorithm for producing “AKS pseudoprimes” would still produce actual primes in the real world, this situation would be rather awkward.
The problem with the correctness of AKS in is proving the existence of a suitable parameter
is proving the existence of a suitable parameter  (as in Lemma 3 of Terry Tao’s post on AKS). The simple proof requires finding a small prime
(as in Lemma 3 of Terry Tao’s post on AKS). The simple proof requires finding a small prime  that does not divide
that does not divide 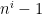 for
for 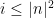 . So this seems to require the infinitude of prime lengths, i.e., a proof of
. So this seems to require the infinitude of prime lengths, i.e., a proof of
(Note that the quantifiers in are sharply bounded.) This looks a lot easier to tackle than the infinitude of primes, but it is still not that easy. Indeed, this is a lot like trying to prove the infinitude of primes in
are sharply bounded.) This looks a lot easier to tackle than the infinitude of primes, but it is still not that easy. Indeed, this is a lot like trying to prove the infinitude of primes in 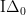 , which is an open problem. I don’t know how to do it, so let me pose it as a problem.
, which is an open problem. I don’t know how to do it, so let me pose it as a problem.
Problem: Prove the infinitude of prime lengths in .
.
A negative answer would be fine, but be aware that negative answer would also solve negatively the question of the infinitude of primes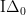 .
.
This difficulty suggests the possibility of working in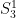 instead. This system is just like
instead. This system is just like  except that it has a new basic function symbol
except that it has a new basic function symbol  . (Yes, there is a whole hierarchy of sharp functions, each of which has subexponential growth.) In
. (Yes, there is a whole hierarchy of sharp functions, each of which has subexponential growth.) In 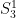 the lengths are closed under the sharp operation and the PWW proof in
the lengths are closed under the sharp operation and the PWW proof in  can be reproduced for lengths. I’ve heard it claimed that the Witnessing Theorem above generalizes to
can be reproduced for lengths. I’ve heard it claimed that the Witnessing Theorem above generalizes to 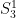 with “polynomial” replaced by “ever-so-slightly-superpolynomial” (i.e., bounded by
with “polynomial” replaced by “ever-so-slightly-superpolynomial” (i.e., bounded by  where
where 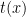 is a term of
is a term of 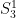 ), which is likely true but I never saw a proof…
), which is likely true but I never saw a proof…
Comment by François Dorais — August 15, 2009 @ 10:40 pm |
Here’s an idea for the problem. Given a length use a number
use a number  of length
of length  to do a sieve of Eratosthenes. Place a 1 bit in the
to do a sieve of Eratosthenes. Place a 1 bit in the  -th digit of
-th digit of  iff
iff  is a multiple of some
is a multiple of some  . Show by induction on
. Show by induction on  (or PIND on
(or PIND on  ) that
) that  has at least one 0 bit beyond the
has at least one 0 bit beyond the  -th. Anyway, this doesn’t immediately give the right parameter
-th. Anyway, this doesn’t immediately give the right parameter  , but a similar trick might work…
, but a similar trick might work…
Comment by François Dorais — August 16, 2009 @ 12:17 am |
The trick above allows us to count just about anything that only involves only length-sized numbers. So basic sieve methods should go through and give lower bounds on the density of length primes. This is enough to pick a suitable parameter (which doesn’t have to be optimal since any
(which doesn’t have to be optimal since any  would be just fine for our purposes).
would be just fine for our purposes).
Propositions 4 and 5 (again referring to Terry Tao’s presentation of AKS) are more problematic since is too big to count. Proving that the various products in the proof of proposition 4 are distinct is fine since the polynomials all have length-size degree. The little pigeonhole trick at the start of the proof proposition 5 is fine since the exponents
is too big to count. Proving that the various products in the proof of proposition 4 are distinct is fine since the polynomials all have length-size degree. The little pigeonhole trick at the start of the proof proposition 5 is fine since the exponents 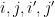 are all length-size. The final part of the proof of proposition 5 is problematic.
are all length-size. The final part of the proof of proposition 5 is problematic.
It seems that this boils down to another pigeonhole problem. This one is a little different since formulating it as an injection from![{[0,2^t]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C2%5Et%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) to
to ![{[0,n^{\sqrt{t}}]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2Cn%5E%7B%5Csqrt%7Bt%7D%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) seems to require solving discrete logarithm problem! Maybe there’s a better way to think about this?
seems to require solving discrete logarithm problem! Maybe there’s a better way to think about this?
Comment by François Dorais — August 16, 2009 @ 3:35 am |
I think it’s time to recap some and draw some preliminary conclusions.
Here is a quick guide for those who are unfamiliar with bounded arithmetic: The system is the essentially the minimal system of arithmetic that can formalize all polynomial time algorithms. The system
is the essentially the minimal system of arithmetic that can formalize all polynomial time algorithms. The system  is marginally stronger and allows some simple search algorithms (usually optimization algorithms) to be formalized too. So “provable in
is marginally stronger and allows some simple search algorithms (usually optimization algorithms) to be formalized too. So “provable in  ” can be read as provable using exclusively polynomial-time methods. Similarly, “provable in
” can be read as provable using exclusively polynomial-time methods. Similarly, “provable in  ” can be read as provable using polynomial-time methods and some simple optimization methods, but nothing else.
” can be read as provable using polynomial-time methods and some simple optimization methods, but nothing else.
More precisely, here are the two basic facts which stem from the witnessing theorems of bounded arithmetic:
(1) From a proof of the infinitude of AKS-primes in one can automatically extract a polynomial time algorithm for producing primes (in the real world).
one can automatically extract a polynomial time algorithm for producing primes (in the real world).
(2) From a proof of the infinitude of AKS-primes in one can automatically extract a polynomial local search (PLS) algorithm for producing primes (in the real world).
one can automatically extract a polynomial local search (PLS) algorithm for producing primes (in the real world).
Since the AKS theorem does not appear to be formalizable in , I use “AKS-prime” for numbers that pass the AKS test and “prime” for numbers without proper divisors. (Of course, there is no such distinction in the real world.) A PLS algorithm wouldn’t be as good as a polytime algorithm, but such an algorithm would show that finding primes is either not NP-hard or NP = co-NP. See also the recent work of Beckmann and Buss [http://www.math.ucsd.edu/~sbuss/ResearchWeb/piPLS/] which allows to draw similar conclusions from proofs in
, I use “AKS-prime” for numbers that pass the AKS test and “prime” for numbers without proper divisors. (Of course, there is no such distinction in the real world.) A PLS algorithm wouldn’t be as good as a polytime algorithm, but such an algorithm would show that finding primes is either not NP-hard or NP = co-NP. See also the recent work of Beckmann and Buss [http://www.math.ucsd.edu/~sbuss/ResearchWeb/piPLS/] which allows to draw similar conclusions from proofs in  for
for  .
.
The line of thought using a factoring oracle and relating finding primes with some pigeonhole principles has some sketchy aspects and I can’t draw anything very useful from it at this time. Basically, while the factoring oracle may be inoffensive, I have a hard time convincing myself of that. So I can only draw conclusions from a proof of polytime factorization, which is even more unlikely than polytime factorization.
proof of polytime factorization, which is even more unlikely than polytime factorization.
Now for some preliminary conclusions, which are only heuristic but are worth keeping in mind.
While I initially thought that the non-provability of the AKS theorem in would be a negative, I now realize that it could be a blessing. Indeed, it suggests that AKS-like congruences may be more amenable to polynomial time attacks than pure divisibility (e.g. attacks using sieves and prime density). So Avi Wigderson’s proposal (Research Thread II, comment #18) may deserve more attention than it has been getting thus far. Moreover, result (2) suggests first trying something with an optimization flavor to it.
would be a negative, I now realize that it could be a blessing. Indeed, it suggests that AKS-like congruences may be more amenable to polynomial time attacks than pure divisibility (e.g. attacks using sieves and prime density). So Avi Wigderson’s proposal (Research Thread II, comment #18) may deserve more attention than it has been getting thus far. Moreover, result (2) suggests first trying something with an optimization flavor to it.
While density methods and variations based on divisibility may be somewhat limited for polynomial time attacks, this does not mean that they should be neglected. Indeed, analytic number theory provides a wealth of second-order information about this which may help evade these limitations. Perhaps a hybrid solution of the following type: try solving the AKS congruences using this method; if that fails, then there must be an unusually large number of primes in this small set.
Comment by François Dorais — August 16, 2009 @ 6:21 pm |
Here is the simple formula you are looking for:
arctan(tan(Pi*bernoulli(2*n)*GAMMA(2*n+1)))*(2*n+1)/Pi= 1 for Prime or zero for non-prime!
In log form:
i*(n+1/2)*log((1-tan(Pi*bernoulli(2*n)*GAMMA(2*n+1)))*(2*n+1)/Pi)/(1+tan(Pi*bernoulli(2*n)*GAMMA(2*n+1)))*(2*n+1)/Pi) )= 1 for Prime or zero for non-prime!
Comment by Michael Anthony — March 14, 2010 @ 1:10 pm |
Here’s another suggestion, just using the usual Riemann zeta function: our explicit formula for is
is 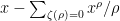 . Now maybe we can work with a small set of values
. Now maybe we can work with a small set of values  , specifically chosen to nullify the effect of a large proportion of the zeros up to height, say,
, specifically chosen to nullify the effect of a large proportion of the zeros up to height, say,  or so. How? Well here is a first attempt: consider
or so. How? Well here is a first attempt: consider 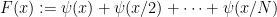 (and of course we will want to show, say, that
(and of course we will want to show, say, that 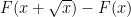 is “large”, so that one of the intervals
is “large”, so that one of the intervals ![[x/n, (x+\sqrt{x})/n]](https://s0.wp.com/latex.php?latex=%5Bx%2Fn%2C+%28x%2B%5Csqrt%7Bx%7D%29%2Fn%5D&bg=ffffff&fg=000000&s=0&c=20201002) has loads of primes). Applying the explicit formula, we find that
has loads of primes). Applying the explicit formula, we find that 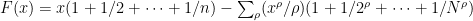 . Notice here that
. Notice here that  is a fragment of the Riemann zeta function, and its closeness to $\latex \zeta(s)$ can be determined through the usual integration-by-parts analytic continuation
is a fragment of the Riemann zeta function, and its closeness to $\latex \zeta(s)$ can be determined through the usual integration-by-parts analytic continuation 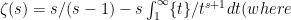 \{t\}$ is the fractional part of
\{t\}$ is the fractional part of  ) for
) for  . But we know that
. But we know that  , so I think this says that our Dirichlet polynomials should all be close to
, so I think this says that our Dirichlet polynomials should all be close to 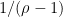 (I would need to check my calculations) when evaluated at these roots
(I would need to check my calculations) when evaluated at these roots 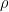 . If this is correct, then we get a formula something like
. If this is correct, then we get a formula something like  , for some error
, for some error 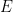 . The fact that we get essentially a
. The fact that we get essentially a  in the denominator is good news, assuming I haven’t made an error.
in the denominator is good news, assuming I haven’t made an error.
Assuming this is all correct, the skeptic in me says that when the dust has settled we get no gain whatsoever.
Comment by Ernie Croot — August 14, 2009 @ 4:11 pm |
Cramér’s conjecture would permit one to find a prime by testing all the integers in a single very short interval. Does the problem get easier by allowing to test the integers in a collection of widely scattered very short intervals? The question is inspired by the observation that Chebyshev’s method allows us to count weighted prime powers in the set
with extreme precision, in fact
What I am suggesting is, maybe the explicit formula approach can be made more powerful with the extra flexibility of searching in several very short intervals. If they are not too many, but are very short, the additional work will not be sgnificant.
Comment by Anon — August 14, 2009 @ 5:21 pm |
I forgot to say that what I am suggesting is a slight elaboration on Ernie’s strategy, to consider something like
$\psi(x + h(x)) – \psi(x) + \psi(c_2x + h_2(x) – \psi(c_2x) + \cdots + \psi(c_m + h_m(x)) – \psi(c_mx)$
with suitable $c_2,\ldots,c_m$ and $h(x),h_1(x),\ldots,h_m(x)$ to knock out terms in the explicit formula. Here $m$ could be as large as a power of $\log(x)$.
Comment by Anon — August 14, 2009 @ 5:40 pm |
That *may* work, but I would think you will need the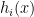 to be quite large (
to be quite large ( or so — which is what we are aiming to slightly improve after all), but I doubt you could knock out lots of terms with
or so — which is what we are aiming to slightly improve after all), but I doubt you could knock out lots of terms with  only of size a power of log — with only a power of log number of terms I would think you would start losing control over the corresponding terms in the explicit formula for zeros a little bigger than
only of size a power of log — with only a power of log number of terms I would think you would start losing control over the corresponding terms in the explicit formula for zeros a little bigger than  itself (which is a power of log).
itself (which is a power of log).
A serious problem with this sort of approach is that you don’t know ahead of time where the zeros of zeta are located on the half-line (assuming RH), and so you are sort of forced to choose the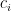 ‘s and the
‘s and the 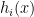 ‘s to conform to some short piece of the zeta function. Well, there may be other nice choices out there (like terms of zeta smoothed in some way, or maybe terms coming from a short Euler product, or maybe a short segment of a completely different zeta function with which you play the usual zero-repulsion games), but if so then I would think you don’t get anything much better.
‘s to conform to some short piece of the zeta function. Well, there may be other nice choices out there (like terms of zeta smoothed in some way, or maybe terms coming from a short Euler product, or maybe a short segment of a completely different zeta function with which you play the usual zero-repulsion games), but if so then I would think you don’t get anything much better.
It just occurred to me that maybe one can modify an idea of Jean Louis Nicolas (on a completely unrelated sort of problem). I’ll think about it…
Comment by Ernie Croot — August 14, 2009 @ 7:21 pm |
I just realized I think there is a factor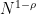 missing in my calculations. Probably this means that one would need to do some smoothing (of the Dirichlet polynomial) for there to be any chance of finding primes more quickly by this method. At any rate, I don’t think these methods have a chance of breaking the square-root barrier.
missing in my calculations. Probably this means that one would need to do some smoothing (of the Dirichlet polynomial) for there to be any chance of finding primes more quickly by this method. At any rate, I don’t think these methods have a chance of breaking the square-root barrier.
Here is the calculation in detail: for arbitrarily small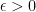 we have
we have ![\sum_{n = 1}^N 1/n^s = \int_{1-\epsilon}^N d [x]/x^s = [x]/x^s |_{1-\epsilon}^N + s \int_{1-\epsilon}^N [x] dx/x^{s+1}](https://s0.wp.com/latex.php?latex=%5Csum_%7Bn+%3D+1%7D%5EN+1%2Fn%5Es+%3D+%5Cint_%7B1-%5Cepsilon%7D%5EN+d+%5Bx%5D%2Fx%5Es+%3D++%5Bx%5D%2Fx%5Es++%7C_%7B1-%5Cepsilon%7D%5EN+%2B+s+%5Cint_%7B1-%5Cepsilon%7D%5EN+%5Bx%5D+dx%2Fx%5E%7Bs%2B1%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Here,
. Here, ![[x] = x - \{x\}](https://s0.wp.com/latex.php?latex=%5Bx%5D+%3D+x+-+%5C%7Bx%5C%7D&bg=ffffff&fg=000000&s=0&c=20201002) , where
, where  denotes the fractional part of
denotes the fractional part of  . Rewriting the
. Rewriting the ![[x]](https://s0.wp.com/latex.php?latex=%5Bx%5D&bg=ffffff&fg=000000&s=0&c=20201002) in the integral as
in the integral as  , we get that the Dirichlet polynomial is
, we get that the Dirichlet polynomial is 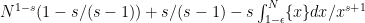 . Now, these last two terms here are approximately
. Now, these last two terms here are approximately 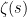 for
for 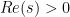 and
and  large, because
large, because  , making the integral absolutely convergent — of course we are using here the formula
, making the integral absolutely convergent — of course we are using here the formula 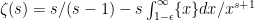 . If we have
. If we have  , then, we get that our Dirichlet polynomial is approximately
, then, we get that our Dirichlet polynomial is approximately  .
.
Comment by Ernie Croot — August 15, 2009 @ 6:05 pm |
Please correct typo in Gamma…Gamma(2*n)>> Gamma(2*n+1), In my paper primes and the Riemann Hypothesis, I show that the primes obey, the relation
frac(theta)=arctan(tan(theta)). You see the primes obey this rule for
theta = Pi*bernoulli(2*n)*Gamma(2*n+1), only if 2*n+1 is a prime. The function theta is a consequence of the Riemann Hypothesis: s=1/2+i*tan(theta)/2.
In fact, I show that:
Zeta(s) = sum(-2^nu*bernoulli(nu)*GAMMA(1-s)/(factorial(nu)*GAMMA(-s-nu+2)), nu = 0 .. infinity); and that when the function vanishes, s/(1-s) = (1/2+(1/2*I)*tan(theta))/(1/2-(1/2*I)*tan(theta))= exp(theta) iff RH is true. The connection with primes is obvious, since when s=-2*n and 2*n+1 is a prime, the function takes an exponential form, and von-Staudt Clausen makes it clear the primes can be counted.
Comment by Michael Anthony — March 14, 2010 @ 12:50 pm |
Here is an elementary observation, which replaces the problem of finding an integer with a factor in a range with that of finding an integer without a factor in a range.
Suppose one is looking for a prime larger than u. Observe that if a number does not have any prime factor larger than u, then it must have a factor in the interval
does not have any prime factor larger than u, then it must have a factor in the interval ![[u,u^2]](https://s0.wp.com/latex.php?latex=%5Bu%2Cu%5E2%5D&bg=ffffff&fg=000000&s=0&c=20201002) , by multiplying the prime factors of n (which are all at most u) one at a time until one falls into this interval. In fact, given any number
, by multiplying the prime factors of n (which are all at most u) one at a time until one falls into this interval. In fact, given any number 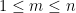 , one must have a factor in the interval
, one must have a factor in the interval ![[m,mu]](https://s0.wp.com/latex.php?latex=%5Bm%2Cmu%5D&bg=ffffff&fg=000000&s=0&c=20201002) by the same reasoning.
by the same reasoning.
So, to find a prime larger than u in at most a steps, one just needs to find an interval![[n,n+a]](https://s0.wp.com/latex.php?latex=%5Bn%2Cn%2Ba%5D&bg=ffffff&fg=000000&s=0&c=20201002) and an interval
and an interval ![[m,mu]](https://s0.wp.com/latex.php?latex=%5Bm%2Cmu%5D&bg=ffffff&fg=000000&s=0&c=20201002) with
with  such that the multiples of all the integers in
such that the multiples of all the integers in ![[m,mu]](https://s0.wp.com/latex.php?latex=%5Bm%2Cmu%5D&bg=ffffff&fg=000000&s=0&c=20201002) do not fully cover
do not fully cover ![[n,n+a]](https://s0.wp.com/latex.php?latex=%5Bn%2Cn%2Ba%5D&bg=ffffff&fg=000000&s=0&c=20201002) .
.
This seems beyond the reach of sieve theory, but at least we no longer have the word “prime” in the problem…
Comment by Terence Tao — August 15, 2009 @ 3:39 am |
Here is a variant of the above idea.
Suppose we are given a factoring oracle that factors k-digit numbers in O(1) time. What’s the largest prime we can currently generate in O(k) time? Trivially we can get a prime of size k or so (up to logs) by scanning [k+1,2k] for primes. If one assumes ABC and factors all the numbers in, say,![[2^k+1, 2^k+k]](https://s0.wp.com/latex.php?latex=%5B2%5Ek%2B1%2C+2%5Ek%2Bk%5D&bg=ffffff&fg=000000&s=0&c=20201002) , one can get a prime of size
, one can get a prime of size  at least (see my comment in II.10). But this is so far the best known.
at least (see my comment in II.10). But this is so far the best known.
Suppose we wanted to show that![[2^k+1,2^k+k]](https://s0.wp.com/latex.php?latex=%5B2%5Ek%2B1%2C2%5Ek%2Bk%5D&bg=ffffff&fg=000000&s=0&c=20201002) had an integer with a prime factor of at least
had an integer with a prime factor of at least  , say. If not, then all numbers here are
, say. If not, then all numbers here are  -smooth. I think this (perhaps with a dash of ABC) shows that all numbers here have a huge number of divisors –
-smooth. I think this (perhaps with a dash of ABC) shows that all numbers here have a huge number of divisors – 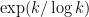 or so. So perhaps we can show that the divisor function
or so. So perhaps we can show that the divisor function  cannot be so huge on this interval?
cannot be so huge on this interval?
Comment by Terence Tao — August 15, 2009 @ 3:10 pm |
This might already have been discussed… Let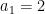 , and
, and  be the largest prime factor of
be the largest prime factor of 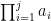 . Since we have a factoring oracle, this is a deterministic way of generating primes, however, what is the best known lower bound on $\latex a_j$? It increases quite rapidly but it is not guaranteed that
. Since we have a factoring oracle, this is a deterministic way of generating primes, however, what is the best known lower bound on $\latex a_j$? It increases quite rapidly but it is not guaranteed that 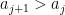 . For example, the first elements of this sentence are
. For example, the first elements of this sentence are  .
.
Comment by Anonymous — August 16, 2009 @ 1:41 am |
I think the lower bound is something like 53. It will not go through all values there is a proof that some lower values are forbidden and it is not monotonic but I don’t think there are any nice lower bounds.
Comment by Kristal Cantwell — August 16, 2009 @ 3:25 am |
[…] current discussion thread for this project is here. Michael Nielsen has a wiki page that summarizes the known results and current ideas. Finally, […]
Pingback by Deterministic way of finding primes « Who groks in beauty? — August 16, 2009 @ 1:51 am |
I think that one can compute the parity of using only
using only  or so bit operations, but maybe I am mistaken. If I am right, then if one knows that, say, the interval
or so bit operations, but maybe I am mistaken. If I am right, then if one knows that, say, the interval ![[x,2x]](https://s0.wp.com/latex.php?latex=%5Bx%2C2x%5D&bg=ffffff&fg=000000&s=0&c=20201002) contains an odd number of primes (as given to one by an oracle, perhaps), then one can use a binary search to locate one using only about
contains an odd number of primes (as given to one by an oracle, perhaps), then one can use a binary search to locate one using only about  (times some logs) or so bit operations.
(times some logs) or so bit operations.
Here is the idea: it is fairly easy to compute
in time or so, using the fact that for
or so, using the fact that for  not a square,
not a square, 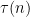 is twice the number of divisors of
is twice the number of divisors of  that are less than
that are less than 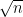 ; so, roughly, forgetting the contribution of the squares, the sum is
; so, roughly, forgetting the contribution of the squares, the sum is
Consider S modulo 4. An individual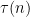 will be divisible by 4 if there are at least two primes that each divide
will be divisible by 4 if there are at least two primes that each divide  to an odd power, or a single prime that divides
to an odd power, or a single prime that divides  to a power that is 3 mod 4. So, the only
to a power that is 3 mod 4. So, the only  ‘s for which
‘s for which 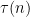 is not divisible by 4 are the numbers of the form
is not divisible by 4 are the numbers of the form 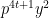 ,
,  is prime not dividing
is prime not dividing  , along with the squares; and, we have that
, along with the squares; and, we have that  . This means that
. This means that
Note that this last sum can be computed using only about or so bit operations; and so, using only this many bit operations we can easily compute the parity of
or so bit operations; and so, using only this many bit operations we can easily compute the parity of
Taking into account the fact that there are at most numbers of the form
numbers of the form  ,
,  , it is easy to see that we can just as easily compute the parity of
, it is easy to see that we can just as easily compute the parity of
using only or so bit operations. But in fact we can just as quickly evaluate the parity of the sum
or so bit operations. But in fact we can just as quickly evaluate the parity of the sum
where will be chosen to depend on a parameter
will be chosen to depend on a parameter 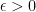 below. The reason we can as quickly evaluate this sum (well, up to a factor
below. The reason we can as quickly evaluate this sum (well, up to a factor 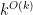 or so) is that we just need to restrict our initial sum over
or so) is that we just need to restrict our initial sum over  to those
to those  that are coprime to
that are coprime to 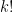 .
.
Now let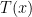 denote the time required to compute
denote the time required to compute  modulo 2. Then clearly we have that
modulo 2. Then clearly we have that
since to compute the parity of we just need to compute
we just need to compute  mod 2, and then the terms
mod 2, and then the terms 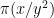 mod 2.
mod 2.
If we have that , for
, for 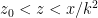 , say, then we deduce that
, say, then we deduce that
For big enough in terms of
big enough in terms of  this should be smaller than
this should be smaller than 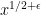 . So it seems to me that we have a quick algorithm for computing the parity of
. So it seems to me that we have a quick algorithm for computing the parity of  , assuming I am not overlooking something obvious. I feel like I must be overlooking something — it can’t be this simple, can it?
, assuming I am not overlooking something obvious. I feel like I must be overlooking something — it can’t be this simple, can it?
Assuming this is right, maybe a similar method will allow us to compute mod 3, mod 5, …, just as easily, and therefore
mod 3, mod 5, …, just as easily, and therefore  itself via the Chinese Remainder Theorem.
itself via the Chinese Remainder Theorem.
Comment by Ernie Croot — August 16, 2009 @ 2:15 pm |
One issue that may be a concern is that a given integer n could have multiple representations of the form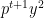 , so one would have to take this into account.
, so one would have to take this into account.
A related observation: if f(n) and g(n) are arithmetic functions whose partial sums can be computed in time, then the Dirichlet convolution f*g can also be computed in
time, then the Dirichlet convolution f*g can also be computed in  time by the Gauss hyperbola method. (This is implicit in your first step, as
time by the Gauss hyperbola method. (This is implicit in your first step, as  is the Dirichlet convolution of 1 with 1.) Unfortunately, there is a big difference between the “smooth” arithmetic functions (whose Dirichlet series have no poles in the critical strip) and the “rough” ones (where there are plenty of poles). One can’t get from the former to the latter by Dirichlet convolution. 1 and
is the Dirichlet convolution of 1 with 1.) Unfortunately, there is a big difference between the “smooth” arithmetic functions (whose Dirichlet series have no poles in the critical strip) and the “rough” ones (where there are plenty of poles). One can’t get from the former to the latter by Dirichlet convolution. 1 and  are examples of the former, while
are examples of the former, while  and
and  are examples of the latter. Jumping from the former to the latter seems related to me to the infamous “parity problem”…
are examples of the latter. Jumping from the former to the latter seems related to me to the infamous “parity problem”…
Comment by Terence Tao — August 16, 2009 @ 3:20 pm |
I understand what you are saying, and in fact I had the same reservations (knowing that functions like tau behave rather differently from mu, say). But I don’t see where the problem is. Following your comment, I thought maybe it was in going from S’ to S” (where the coprimeness condition is dropped), but that can’t be where the problem lies because from the fact that we only have to worry about primes smaller than
we only have to worry about primes smaller than  in computing S''. Of course we also have that a number of the form
in computing S''. Of course we also have that a number of the form  has a unique such representation, so that problem is avoided too; as is the problem of uniqueness of representation of
has a unique such representation, so that problem is avoided too; as is the problem of uniqueness of representation of 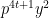 , given that
, given that  .
.
Assuming that the algorithm is correct (and I have tried hard to see where it could be wrong, and still feel that there has to be an error somewhere), one thing that *maybe* takes care of the parity concerns is the fact that the algorithm is useless as far as locating primes, unless one is given that there are an odd number of primes in some long interval to begin with — i.e. unless one is given some initial non-trivial parity information about the prime counting function on some interval.
Comment by Ernie Croot — August 17, 2009 @ 1:59 am |
I haven’t found a problem in first reading myself; philosophically, I don’t see a problem with the parity of being computable in
being computable in  time (I’m thinking by analogy with the class numbers of quadratic fields, which are very mysterious and seem unpredictable, except that their parity is known — since Gauss — in terms of the factorization of the discriminant of the field).
time (I’m thinking by analogy with the class numbers of quadratic fields, which are very mysterious and seem unpredictable, except that their parity is known — since Gauss — in terms of the factorization of the discriminant of the field).
Comment by Emmanuel Kowalski — August 17, 2009 @ 2:17 am |
Let me also point out something else: Selberg’s original formulation of the “parity problem” does not apply here. In that formulation he said that you could take a set of integers having an even number of prime factors, satisfy all the sieve axioms, and yet obviously the set has no primes. But in the algorithm I described we are working mod 2 — mod 2 information is so fine that the “main term” parity objection of Selberg simply doesn’t apply. Furthermore, information about sums of arithmetical functions mod small primes also should escape parity-type objections. This perhaps gives one a ray of hope of escaping the usual “analytic obstructions” to determining quickly — perhaps there is a mod 3, mod 5, … version of the argument (again, assuming it is correct) that will allow us to determine
quickly — perhaps there is a mod 3, mod 5, … version of the argument (again, assuming it is correct) that will allow us to determine  quickly via CRT (in other words, `arithmetical [i.e. algebraic] methods’ give us a way out of `analytic obstructions’).
quickly via CRT (in other words, `arithmetical [i.e. algebraic] methods’ give us a way out of `analytic obstructions’).
Comment by Ernie Croot — August 17, 2009 @ 3:51 am |
OK, I went through it and it looks correct to me – though I haven’t seen anything like it before, so I’m still getting used to it. Emmanuel’s comment is reassuring, though.
I guess the next thing is to look at what tau(n) mod 8 tells us… some combination of the parity of the semiprime counting function and pi(n) mod 4? Unfortunately the hyperbola method doesn’t seem to let us quickly compute the former given the parity of pi(n), but I didn’t check this too carefully.
If one wants mod 3 information, I think one may have to work with the second divisor function since one will want
since one will want 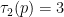 …
…
Comment by Terence Tao — August 17, 2009 @ 3:57 am |
Hmm, I can’t figure out how to compute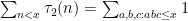 in time
in time  ; the best I can do is
; the best I can do is  or so. (My earlier comment about how the Dirichlet convolution of two quantities whose partial sums were square-root-computable also had partial sums that were square-root computable was incorrect.) That's a shame, because
or so. (My earlier comment about how the Dirichlet convolution of two quantities whose partial sums were square-root-computable also had partial sums that were square-root computable was incorrect.) That's a shame, because 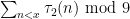 does seem to be encoding something about
does seem to be encoding something about 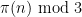 , modulo simpler terms…
, modulo simpler terms…
Comment by Terence Tao — August 17, 2009 @ 4:38 am |
Here’s a suggestion for how to do this, and perhaps all the higher divisor sums as well, though I am not sure it will work: fix an integer N. Then, since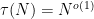 we also get
we also get  , for any
, for any  . This *suggests* to me that the lattice points in the region
. This *suggests* to me that the lattice points in the region 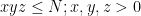 , can be partitioned into those in at most
, can be partitioned into those in at most  integer simplices (well, certainly if
integer simplices (well, certainly if  were at least
were at least  or so we would have no chance at all with this type of geometric approach); and if so we could use an off-the-shelf algorithm to count lattice points in simplices (e.g. I think Jesus de Loera has some algorithms to do this; and I think also Barvinok has a nice analytic algorithm). Of course, one cannot just connect up the lattice points along the boundary
or so we would have no chance at all with this type of geometric approach); and if so we could use an off-the-shelf algorithm to count lattice points in simplices (e.g. I think Jesus de Loera has some algorithms to do this; and I think also Barvinok has a nice analytic algorithm). Of course, one cannot just connect up the lattice points along the boundary  to form some kind of approximate triangulation of the region, because our region
to form some kind of approximate triangulation of the region, because our region 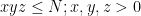 is highly non-convex, but maybe there is some kind of nice simplicial complex that one can find easily.
is highly non-convex, but maybe there is some kind of nice simplicial complex that one can find easily.
Comment by Ernie Croot — August 17, 2009 @ 1:29 pm |
This sounds promising. I did some further computations and it does indeed seem that if one can compute in
in  time then one should be able to compute
time then one should be able to compute  in
in  time, because the latter is essentially the contribution of the square-free numbers to the former, and the numbers which have a square factor can be recursively removed (perhaps with a dash of Mobius inversion) within the square root time budget. We need to do this for k out to about
time, because the latter is essentially the contribution of the square-free numbers to the former, and the numbers which have a square factor can be recursively removed (perhaps with a dash of Mobius inversion) within the square root time budget. We need to do this for k out to about  or so in order to get the chinese remainder theorem to detect changes in
or so in order to get the chinese remainder theorem to detect changes in  deterministically (although probabilistically one could do this with far fewer moduli), so I guess we need to keep the dependences on k to be subexponential, but perhaps we should defer that problem until we can at least solve the k=2 issue.
deterministically (although probabilistically one could do this with far fewer moduli), so I guess we need to keep the dependences on k to be subexponential, but perhaps we should defer that problem until we can at least solve the k=2 issue.
I had two thoughts that may be relevant. Firstly, if one assumes access to memory as well as
memory as well as  time, then one can precompute just about any arithmetical function, say
time, then one can precompute just about any arithmetical function, say  , for
, for 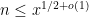 , and then by an FFT one can also compute the partial sums
, and then by an FFT one can also compute the partial sums 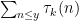 for
for  . I don’t immediately see how this could be useful but it may come in handy later.
. I don’t immediately see how this could be useful but it may come in handy later.
Secondly, it may be that k=2 is in fact the worst case; as k increases one may be able to approach again. My intuition here is that when working out a sum
again. My intuition here is that when working out a sum  , one should (usually) be able to find a subset of the
, one should (usually) be able to find a subset of the  whose product is relatively close to
whose product is relatively close to  , and the degree of approximation should get better as k increases. Unfortunately I don’t know how to exploit this fact to get an efficient algorithm, and also there are the tail cases when a few of the
, and the degree of approximation should get better as k increases. Unfortunately I don’t know how to exploit this fact to get an efficient algorithm, and also there are the tail cases when a few of the 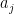 dominate in which one doesn’t get anywhere close to
dominate in which one doesn’t get anywhere close to  . (For this least-significant-digit analysis, one cannot afford to throw away any error terms unless they are divisible by the modulus of interest.)
. (For this least-significant-digit analysis, one cannot afford to throw away any error terms unless they are divisible by the modulus of interest.)
Comment by Terence Tao — August 17, 2009 @ 3:44 pm |
I think I figured out how to do it, following a nice lunch: look at the lattice point counting problem backwards — in other words, instead of trying to count the number of lattice points satisfying , count the number
, count the number 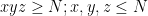 . Unlike the region
. Unlike the region  , this one is convex; and so, one can easily form a polytope where the vertices on
, this one is convex; and so, one can easily form a polytope where the vertices on  form a boundary.
form a boundary.
I think the same should work in higher dimensions, after some modification. The point is that I think we no longer have convexity when we go to higher dimensions, but we can decompose the polytope into a small number of convex pieces.
Comment by Ernie Croot — August 17, 2009 @ 4:09 pm |
This is a neat idea, but there is one possible problem I see – perhaps there are lattice points with that are not within the convex hull of the lattice points with
that are not within the convex hull of the lattice points with  ? Consider for instance the case when N is prime. (Of course, in this case we are done immediately with our finding primes problem, but still…)
? Consider for instance the case when N is prime. (Of course, in this case we are done immediately with our finding primes problem, but still…)
Comment by Terence Tao — August 17, 2009 @ 4:32 pm |
Ok, that was silly of me. Perhaps, though, there is a way to find the other points on the convex hull, by considering solutions to for
for  near to
near to  . Actually, I guess if
. Actually, I guess if  has a small number of prime factors then this won’t do, because the set of
has a small number of prime factors then this won’t do, because the set of  that one would have to look through is quite large.
that one would have to look through is quite large.
When I get some free time I will think about this some more…
Comment by Ernie Croot — August 17, 2009 @ 4:47 pm
This reminds me of results in the thesis of Fouvry which roughly state that if one understands (in the sieve sense) a certain number of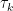 -functions, then one can get information beyond the Bombieri-Vinogradov theorem concerning the primes. Unfortunately, I can’t find this mentioned in the MathSciNet reviews of his early papers, and possibly that part of the thesis was not published. I will try to have a look at the original when I can.
-functions, then one can get information beyond the Bombieri-Vinogradov theorem concerning the primes. Unfortunately, I can’t find this mentioned in the MathSciNet reviews of his early papers, and possibly that part of the thesis was not published. I will try to have a look at the original when I can.
Analytically, the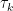 functions become worse and worse when
functions become worse and worse when  increases (this is related to their Dirichlet series having “degree”
increases (this is related to their Dirichlet series having “degree”  ). In particular, the error term in the summation formula becomes worse with
). In particular, the error term in the summation formula becomes worse with  , unless one uses something like the Lindelöf Hypothesis.
, unless one uses something like the Lindelöf Hypothesis.
Comment by Emmanuel Kowalski — August 17, 2009 @ 4:19 pm |
Related to this approach, there is a nice identity of Linnik. Let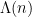 be the van Mangoldt function and
be the van Mangoldt function and  the number of representations of
the number of representations of  as ordered products of integers greater than 1, then
as ordered products of integers greater than 1, then 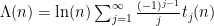 . The sum is rather short since
. The sum is rather short since  for
for  larger than about
larger than about 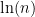 . Note that the function
. Note that the function  is related to
is related to 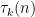 by the relation
by the relation  . Again,
. Again, 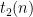 is computable in
is computable in  steps, however
steps, however  , for larger
, for larger  , appears more complicated. Curiously this is a fundamental ingredient in the Friedlander and Iwaniec work.
, appears more complicated. Curiously this is a fundamental ingredient in the Friedlander and Iwaniec work.
Comment by Mark Lewko — August 17, 2009 @ 6:32 pm |
Three quick comments:
(1) I was slightly confused when I wrote the above comment. However, I think the observation is still useful, since . So to find
. So to find 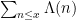 we only need to know
we only need to know 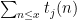 for
for  . Of course we could use the Chinese remainder theorem idea instead here.
. Of course we could use the Chinese remainder theorem idea instead here.
2) I don’t seem to be able to compute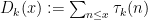 in less than
in less than 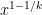 steps. To get this let
steps. To get this let 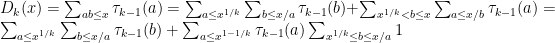 . So, at least for this approach, we essentially need to compute
. So, at least for this approach, we essentially need to compute 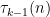 for
for 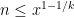 . This agrees with Tao's computation since my
. This agrees with Tao's computation since my 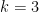 is his
is his  . This is reminiscent of the trivial divisor problem estimates, which brings me to
. This is reminiscent of the trivial divisor problem estimates, which brings me to
(3) It is interesting though that we have reduced the computation of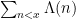 to the computation of
to the computation of  for
for  . At this point, one might forget about computing the values
. At this point, one might forget about computing the values  and plug in estimates for
and plug in estimates for  . These estimates are of the form
. These estimates are of the form 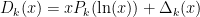 , for explicit polynomials
, for explicit polynomials 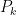 . In our situation we need
. In our situation we need 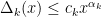 for
for  for all
for all  . As far as I can find there aren't known estimates of this form. However, Titchmarsh conjectures that
. As far as I can find there aren't known estimates of this form. However, Titchmarsh conjectures that 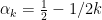 .
.
More specifically we have that . Assuming the binomial coefficients don't do too much damage, this should give us an estimate for
. Assuming the binomial coefficients don't do too much damage, this should give us an estimate for 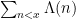 with an error term
with an error term  . So this would get us down to
. So this would get us down to  on Titchmarsh's conjecture. Moreover, if the main term worked out to be
on Titchmarsh's conjecture. Moreover, if the main term worked out to be  (and, again, the binomial coefficients aren't a problem), I think this would show that Titchmarsh's conjecture implies RH. (If I were to guess, the problem with this will be that we need cancellation in the binomial sum.)
(and, again, the binomial coefficients aren't a problem), I think this would show that Titchmarsh's conjecture implies RH. (If I were to guess, the problem with this will be that we need cancellation in the binomial sum.)
Comment by Mark Lewko — August 18, 2009 @ 12:26 am |
2 corrections and a comment:
1) The mangled calculation in the second paragraph should be:

 [Corrected.]
[Corrected.]
2) The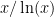 in the last paragraph should just be
in the last paragraph should just be  . [Corrected.]
. [Corrected.]
On reflection, the last paragraph of the previous post is absurd for any number of reasons. Most notably, Titchmarsh's Theory of the Zeta Function gives that (in the notation above) that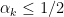 is equivalent to the Lindelof hypothesis. So my casual heuristic at the end of the post could be reworded as "the Lindelof Hypothesis implies RH". In fact the binomial coefficients cause all sorts of problems. Sterling's formula shows that the binomial coefficients get as large as
is equivalent to the Lindelof hypothesis. So my casual heuristic at the end of the post could be reworded as "the Lindelof Hypothesis implies RH". In fact the binomial coefficients cause all sorts of problems. Sterling's formula shows that the binomial coefficients get as large as 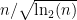 which is near the main term, before multiplying by the error terms
which is near the main term, before multiplying by the error terms 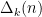 ).
).
On take-a-way from this is that while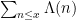 is determind from the values
is determind from the values  's, the relation is very subtle. Specifically, it seems nearly impossible to turn a good estimes for the
's, the relation is very subtle. Specifically, it seems nearly impossible to turn a good estimes for the  's into a good estimate for
's into a good estimate for 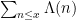 .
.
Comment by Mark Lewko — August 18, 2009 @ 7:42 am |
I have a question about the background. Are the conjectures on the Poisson’s distribution of primes in small intervals, (and the distribution of gaps between primes; and the Hardy Littelwood conjectures) related (or equivalent) to conjectures regarding gaps between zeroes of the zeta function? (I remember hearing a lot about the later question and the relation with random matrix theory but the actual implication to primes is not fresh in my memory (and probably never was)).
In general, (since we are willing to take standard conjectures regarding the zeta function for granted) do we expect properties of Riemann zeta function to have baring on behavior of primes in short (polylog) intervals?
Comment by Gil — August 17, 2009 @ 7:10 am |
Yes, distributional information about primes (and almost primes) in short intervals is more or less equivalent to distributional information about zeroes. For instance, in this paper of Goldston and Montgomery,
http://www.ams.org/mathscinet-getitem?mr=1018376
they show (using RH) that the pair correlation conjecture about zeroes is equivalent to the second moment of primes in short intervals matching the Poisson prediction.
There is a later paper by Bogolmony and Keating,
http://www.ams.org/mathscinet-getitem?mr=1363402
which shows (heuristically, at least) that a sufficiently strong version of the prime tuples conjecture implies the full GUE conjecture, though I am not sure exactly what they do with the error terms in the prime tuples conjecture.
I discuss these sort of issues a little in my blog post,
Of course, all of these facts only give average-case information about primes in short intervals rather than worst-case, so are subject to the razor.
Comment by Terence Tao — August 17, 2009 @ 3:55 pm |
I have three general remarks: If, for example, we can show how to find a large prime in a short interval of integers but we need to start the interval at a random place; or if we can show using a factoring oracle that in such a short interval on average a large prime is present (maybe this is obvious), such results are also interesting “derandomization” results. It is true that they do not save us many random bits and that maybe some general principles (e.g. Nisan’s pseudorandom generator) can save us even more random bits but still it is an interesting form of partial derandomziation. (Derandomization can have the following form: construct a hybrid algorithm of a specific type where one part is deterministic.)
2. The various razors gives us “primes” with unusual (maybe even “statistically unusual”) properties. So it is not impossible that we will be able to come up with plausible conjectures for some anti razor razor.
3.Regarding “Strategy D: Find special sequences of integers that are known to have special types of prime factors, or are known to have unusually high densities of primes.”
I think we should try to come up with some conjectures in the direction that sequences a(n) described by low complexity means cannot have unusually high density of primes or unusually small gaps between primes. And maybe showing negative results will even be slightly easier than positive results. Maybe some negative result of this kind can be proved (or are already known) for sequences based on polynomials. It would be nice to include in such conjectures all the sequences that people (naively) suggested.
We do not want to allow that a(n) be anything computable in time poly(log (n)) because this will allow (more or less) to let a(n) be the nth prime. But anything we can imagine that still allow a(n)=n^7+n^3-5 or a(n)=2^n+1 should be ok.
Is there even a single sequence with higher density of primes known? (even based on some standard conjectures?)
Comment by Gil Kalai — August 17, 2009 @ 5:00 pm |
I was about to say that I was not sure that I understood your remark about the nth prime being computable in time poly(log(n)). But now I think I do. We could define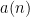 to be the smallest prime greater than
to be the smallest prime greater than  if there is a prime between
if there is a prime between  and
and  , and
, and  otherwise. That will give us far too many primes. Is that the kind of thing you meant?
otherwise. That will give us far too many primes. Is that the kind of thing you meant?
I was also about to suggest low arithmetic complexity of some kind. For example, we could regard the arithmetic complexity of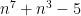 as being at most 8 because one can write it as
as being at most 8 because one can write it as 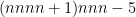 . Here we are allowed to call up
. Here we are allowed to call up  for free. But to get
for free. But to get  takes roughly
takes roughly  operations, by repeated squaring, so it doesn’t help. On the other hand, it is much simpler to get
operations, by repeated squaring, so it doesn’t help. On the other hand, it is much simpler to get  from
from  than it is to get the nth prime from the previous one. Perhaps that could be used in some way. I.e., one asks for bounded arithmetic complexity, but one can call on the previous value, or perhaps even all previous values (provided we can specify them sufficiently simply, or else one might be able to do some silly encodings), of the function.
than it is to get the nth prime from the previous one. Perhaps that could be used in some way. I.e., one asks for bounded arithmetic complexity, but one can call on the previous value, or perhaps even all previous values (provided we can specify them sufficiently simply, or else one might be able to do some silly encodings), of the function.
Comment by gowers — August 17, 2009 @ 5:20 pm |
I was carried away a little, but i want to “prevent” that when a(n) is computed its value is guaranteed to be prime via primality testing algorithm or something like that.
Comment by Gil — August 17, 2009 @ 9:29 pm |
Sorry, my first general remark looks meaningless to me (it is obvious that there are good intervals just from the density). Update: I managed to understand what I meant. Statistical conjectures regarding gaps between primes (which come short of Cramer’s conjecture) allow to reduce the number of random intervals you must look (so the number of random bits when you restrict yourself to this argorithm). Similarly, statistical properties of the number of non-S-smooth numbers in large intervals, (stronger than just what you get from the density of these numbers) will also lead to “saving” some random bits when you insist on an algorithm that looks for large prime factor in large intervals and what very high probabilities for success. Anyway (even without this dubious justification), it seems that the problem of showing that the probability for non-S-smoth numbers in large intervals is very small (rather than 0) is an interesting variation for Gowers’ original suggestion and it is not affected by our razor.
Comment by Gil — August 18, 2009 @ 5:59 pm |
If the result we are trying to prove and we have all constructable numbers with k digits have prime free gaps g of size say k^100 then could the distribution of times still be normal or have tail that is as thin as the normal distribution?
Comment by Kristal Cantwell — August 18, 2009 @ 4:05 pm |
Unfortunately, the answer seems to be yes: the set of constructible numbers is only poly(k) in size, and is thus extremely sparse compared against the set of all k-digit numbers, which is exponential in size. One could have all sorts of pathological behaviour near constructible numbers and still have a perfectly ordinary distributional law on all numbers. (This is closely related to the discussion on “generic primes” on the wiki, and on the “razor” on this thread.)
Comment by Terence Tao — August 18, 2009 @ 4:45 pm |
Let me make a general comment about Cramer’s conjecture, though maybe it has been made before (it’s hard to keep up with all the postings): a much weaker conjecture than Cramer’s, that also would allow us to find a prime number quickly, is the assumption that given , there exists a quickly determinable set
, there exists a quickly determinable set  of size at most
of size at most 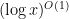 such that
such that  , where
, where  denotes the set of primes up to
denotes the set of primes up to  . The reason this conjecture is nicer than Cramer’s, as far as determining primes quickly, is that it includes under its purview many other types of additive results (Cramer can be interpreted as an additive result of sorts). For example, there is a nice paper by Granville et al on primes plus powers-of-two; and there is a beautiful paper of Christian Elsholtz on something called “Ostmann’s Conjecture” that has some “sieve boot-strapping” ideas that might be useful.
. The reason this conjecture is nicer than Cramer’s, as far as determining primes quickly, is that it includes under its purview many other types of additive results (Cramer can be interpreted as an additive result of sorts). For example, there is a nice paper by Granville et al on primes plus powers-of-two; and there is a beautiful paper of Christian Elsholtz on something called “Ostmann’s Conjecture” that has some “sieve boot-strapping” ideas that might be useful.
—-
I think I will post a lot less frequently to the polymath project, as classes have started back here at Georgia Tech… it’s a pity this project wasn’t started earlier in the summer (I may post something later this week, though, on how to use the Szemeredi-Trotter theorem to locate primes — there are some ideas in an unpublished note I sent to someone once that I think might allow one to do this, but I need to think it over first to see if it is silly).
Comment by Ernie Croot — August 17, 2009 @ 1:58 pm |
Well, one of the great things about this type of collaboration is that (in principle) one can contribute as frequently or as rarely as one wishes… though catching up is indeed a major problem. I should work on the wiki again to try to incorporate the recent progress (including several of your neat ideas)…
One problem with the A+P approach is that it is still subject to the razor; one could delete all the elements of x-A from P and end up with a set of redacted primes which still looks the same as the set of all primes for the purposes of additive combinatorics or the circle method, but for which A+P now omits a single point x. This is basically why results about sums A+B of two dense sets generally have to allow for a small number of exceptions, whereas sums of three dense sets don’t.
But if there is some way to avoid the razor, there may well be a chance here…
Comment by Terence Tao — August 17, 2009 @ 4:26 pm |
I’d like to suggest a pseudorandom generator approach to the problem
that does not hit the wall of proving strong circuit lower bounds.
We want a function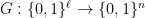
![|\mathrm{Pr}_X[PRIME(X)] - \mathrm{Pr}_Y[PRIME(G(Y))]| \leq 1/n^2](https://s0.wp.com/latex.php?latex=%7C%5Cmathrm%7BPr%7D_X%5BPRIME%28X%29%5D+-+%5Cmathrm%7BPr%7D_Y%5BPRIME%28G%28Y%29%29%5D%7C+%5Cleq+1%2Fn%5E2&bg=ffffff&fg=000000&s=0&c=20201002) (say), where
(say), where  and
and 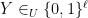 . If
. If  is
is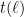 then we can find an
then we can find an  -bit
-bit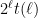 by going through all seeds. This
by going through all seeds. This and
and 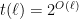 .
.
such that
computable in time
prime in time
is polynomial if
The main idea of the approach is to take a Nisan-Wigderson-looking based on a well-understood Boolean function
based on a well-understood Boolean function
 (instead of a hard Boolean
(instead of a hard Boolean is so simple
is so simple
generator
function as would traditionally be done) and argue that a primality
test is not effective to distinguish the output of this generator from
the uniform distribution. Intuitively, if
that it has very little to do with primality, it is hard to expect
that a primality test can be used to break the generator. Let us try
to make this idea precise.
Here is the Nisan-Wigderson generator construction. Let be a Boolean function. Let
be a Boolean function. Let 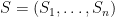 be an
be an  -design, which means that
-design, which means that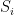 is a subset of
is a subset of  of
of and every two distinct
and every two distinct 
 places. The Nisan-Wigderson generator
places. The Nisan-Wigderson generator
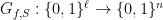 is defined as
is defined as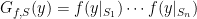 , where
, where
 denotes the restriction of
denotes the restriction of  to the bits in
to the bits in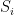 . Think of
. Think of 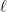 as
as  , of
, of
 as
as 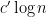 for a
for a 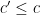 , and of
, and of  as
as 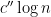 for a
for a 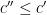 . Such designs
. Such designs
each
cardinality exactly
intersect in at most
follows:
positions
exist.
The analysis of the Nisan-Wigderson generator shows that if is a distinguisher in the sense that
is a distinguisher in the sense that ![\mathrm{Pr}_X[D(X)] - \mathrm{Pr}_Y[D(G(Y))] \ge 1/n^2](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BPr%7D_X%5BD%28X%29%5D+-+%5Cmathrm%7BPr%7D_Y%5BD%28G%28Y%29%29%5D+%5Cge+1%2Fn%5E2&bg=ffffff&fg=000000&s=0&c=20201002) , then the following procedure
, then the following procedure significantly better than guessing:
significantly better than guessing:
predicts
Procedure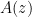 : given
: given  , choose
, choose 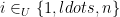 , choose
, choose  , choose
, choose ![s \in_U \{0,1\}^{[\ell]-S_i}](https://s0.wp.com/latex.php?latex=s+%5Cin_U+%5C%7B0%2C1%5C%7D%5E%7B%5B%5Cell%5D-S_i%7D&bg=ffffff&fg=000000&s=0&c=20201002) , let
, let
 be the result of inserting
be the result of inserting  in
in  in
in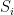 (leaving a string in
(leaving a string in ![\{0,1\}^{[\ell]}](https://s0.wp.com/latex.php?latex=%5C%7B0%2C1%5C%7D%5E%7B%5B%5Cell%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) as a result), let
as a result), let 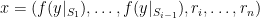 , compute
, compute  , if the
, if the return
return 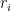 , otherwise return
, otherwise return  .
.
the places dictated by
outcome is
The precise result says that if![\mathrm{Pr}_X[D(X)] - \mathrm{Pr}_Y[D(G(Y))] \ge 1/n^2](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BPr%7D_X%5BD%28X%29%5D+-+%5Cmathrm%7BPr%7D_Y%5BD%28G%28Y%29%29%5D+%5Cge+1%2Fn%5E2&bg=ffffff&fg=000000&s=0&c=20201002) , then
, then ![\mathrm{Pr}_{z,i,r,s}[A(z) = f(z)] \ge 1/2 + 1/n^3](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BPr%7D_%7Bz%2Ci%2Cr%2Cs%7D%5BA%28z%29+%3D+f%28z%29%5D+%5Cge+1%2F2+%2B+1%2Fn%5E3&bg=ffffff&fg=000000&s=0&c=20201002) (note the loss of
(note the loss of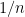 factor from
factor from 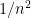 to
to 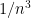 ). This is
). This is
a
proved by the standard hybrid argument.
Now let us interpret the meaning of this when is a
is a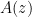 predicts
predicts  by
by -bit number
-bit number  that is
that is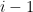 somewhat complicated bits (the first part of
somewhat complicated bits (the first part of
 ) followed by
) followed by 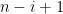 random bits (the second part of
random bits (the second part of
 ) is prime (or non-prime), and returning the
) is prime (or non-prime), and returning the  -th
-th . This is a uniformly chosen number in an interval
. This is a uniformly chosen number in an interval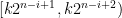 , where
, where  is
is and
and 
 and the design
and the design  . Now, if
. Now, if  and
and
 are chosen sufficiently simple (instead of complicated as
are chosen sufficiently simple (instead of complicated as and show that the
and show that the -th bit of a random
-th bit of a random  chosen uniformly in the random interval
chosen uniformly in the random interval 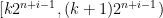 is almost independent of whether
is almost independent of whether  is prime or not. If
is prime or not. If  is a balanced function so that
is a balanced function so that ![\mathrm{Pr}_z[f(z) = 1] = 1/2](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BPr%7D_z%5Bf%28z%29+%3D+1%5D+%3D+1%2F2&bg=ffffff&fg=000000&s=0&c=20201002) , this would contradict the fact that
, this would contradict the fact that
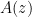 guesses
guesses  significantly better than guessing.
significantly better than guessing.
primality test. The algorithm
checking whether an
composed of
bit of
of the form
chosen uniformly at random in
follows a somewhat complicated distribution depending on the function
the hardness-vs-randomness paradigm suggests), there is a chance that
one can analyse the distribution of
marginal distribution on the
There are tons of simple ‘s one can look at, starting with
‘s one can look at, starting with
 or even
or even  , and
, and (which by the way, need not be strictly a
(which by the way, need not be strictly a
similarly for
design in the sense of having small intersections since that is not
used in the analysis above).
Comment by Albert Atserias — August 17, 2009 @ 2:59 pm |
I like this idea! Doesn’t seem very easy though…
Considering that must be even half the time, we see that
must be even half the time, we see that  must take values 0,1 equally often. Not difficult.
must take values 0,1 equally often. Not difficult.
Considering modulo 3, we see that the probability that
modulo 3, we see that the probability that
must be close to 1/3.
Considering modulo
modulo 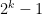 , we get similar restrictions relating the sums
, we get similar restrictions relating the sums
for $a = 0,\dots,k-1$.
Assuming some (perhaps strong) facts regarding the equidistribution of primes in arithmetic progressions, these are potentially the only restrictions on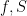 we need to worry about.
we need to worry about.
Choosing very well and
very well and  simple enough, we may be able to control the sums
simple enough, we may be able to control the sums 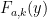 with small perturbations of
with small perturbations of  and get the right probabilities?
and get the right probabilities?
Comment by François Dorais — August 17, 2009 @ 5:13 pm |
Assuming GRH, a distinguishing pair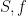 should give a roughly
should give a roughly 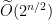 algorithm for producing an approximately
algorithm for producing an approximately  -bit prime. Basically, equidistribution of primes modulo
-bit prime. Basically, equidistribution of primes modulo  prevents small choices of
prevents small choices of  in procedure A from distinguishing since the predictor used is too close to random guessing. For large choices of
in procedure A from distinguishing since the predictor used is too close to random guessing. For large choices of  , the intervals
, the intervals 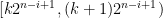 are short enough to scan until we find primes to explain the discrepancy. Since
are short enough to scan until we find primes to explain the discrepancy. Since  only takes
only takes  values modulo
values modulo  we can afford to check them all. (Of course, if we miraculously pick a non-distinguishing pair
we can afford to check them all. (Of course, if we miraculously pick a non-distinguishing pair 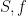 then we have a polytime algorithm!)
then we have a polytime algorithm!)
Maybe there are smart choices of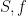 that could eliminate the GRH assumption?
that could eliminate the GRH assumption?
Are you sure being a block design is not necessary?
being a block design is not necessary?
Comment by François Dorais — August 17, 2009 @ 8:11 pm |
About the no-need of to be a design. The small intersection property of
to be a design. The small intersection property of  is only needed by NW when they want to turn the procedure
is only needed by NW when they want to turn the procedure 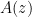 into a small circuit that predicts
into a small circuit that predicts  without using
without using  itself: for fixed
itself: for fixed  that achieve the bias of
that achieve the bias of 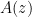 , each
, each 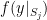 with
with  depends only on
depends only on 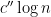 bits of the input
bits of the input  and therefore we can plug a circuit of size
and therefore we can plug a circuit of size  in place of
in place of 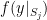 . If
. If  is small enough with respect to
is small enough with respect to 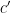 , this leaves a small circuit. But here we do not care getting a circuit so we leave the
, this leaves a small circuit. But here we do not care getting a circuit so we leave the 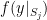 ‘s. Small intersection is not used anywhere else in the analysis of NW.
‘s. Small intersection is not used anywhere else in the analysis of NW.
About your win-win argument. From what I understand here, why ? Let us say we divide by cases
? Let us say we divide by cases 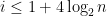 and
and 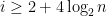 . The first case is ruled out by equidistribution (?) of primes modulo
. The first case is ruled out by equidistribution (?) of primes modulo  as the predictor gets success roughly
as the predictor gets success roughly 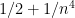 . The second case leaves an interval
. The second case leaves an interval  of length
of length 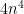 which we can check exhaustively to explain the discrepancy (and hence find primes). But is this what you have in mind? I guess the question is rather: what is the exact result on equidistribution of primes that you plan to use? We might want to choose
which we can check exhaustively to explain the discrepancy (and hence find primes). But is this what you have in mind? I guess the question is rather: what is the exact result on equidistribution of primes that you plan to use? We might want to choose  and
and  so that
so that  is rather uniformly distributed.
is rather uniformly distributed.
Comment by Albert Atserias — August 17, 2009 @ 10:04 pm |
What I wrote was not very clear. I think the main issue is that I am reading the numbers backwards, which is rather confusing, to say the least! When I read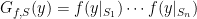 , I think of
, I think of  as the least significant bit, so your intervals are arithmetic progressions in my universe. To clean things up, I’ll redefine
as the least significant bit, so your intervals are arithmetic progressions in my universe. To clean things up, I’ll redefine
so the we avoid the pesky even/odd issue too. So now the prediction algorithm can be restated as follows.
Procedure A: Given . First, pick
. First, pick 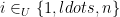 . Then pick
. Then pick  such that
such that  , uniformly at random. Finally, pick
, uniformly at random. Finally, pick 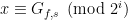 ,
,  , uniformly at random. If
, uniformly at random. If  is prime return
is prime return  otherwise return
otherwise return  (where
(where 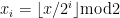 ).
).
Equidistribution of primes then means that for fixed the sets
the sets
all have roughly equal size for odd . Under GRH, the error is something like
. Under GRH, the error is something like  . So when the algorithm picks
. So when the algorithm picks  small, it is pretty much randomly guessing. For large
small, it is pretty much randomly guessing. For large  , the sizes of the
, the sizes of the  can vary wildly, but the arithmetic progression
can vary wildly, but the arithmetic progression  has size
has size 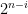 .
.
So the prime finding algorithm runs like this: Pick suitable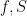 . Compute the numbers
. Compute the numbers  as above for
as above for  (note that
(note that  ). If one of these numbers is prime, then bingo! Otherwise, systematically perturb the few most significant bits of the numbers just computed until a prime is found.
). If one of these numbers is prime, then bingo! Otherwise, systematically perturb the few most significant bits of the numbers just computed until a prime is found.
My earlier scribbles suggest that you under GRH only need to perturb the top half bits of each number, but that may have been slightly optimistic.
Comment by François Dorais — August 17, 2009 @ 11:50 pm |
Ah! I made a silly mistake in my scribbles – I didn’t consider the dependency on the modulus in the GRH estimate. This algorithm is probably a whole lot slower than because of that! I think I’ll let number theorists figure out whether this algorithm is worthwhile…
because of that! I think I’ll let number theorists figure out whether this algorithm is worthwhile…
Comment by François Dorais — August 18, 2009 @ 1:42 am |
I posted some details and discussions around this idea here. The “win-win” twist that I described earlier does indeed give a deterministic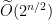 algorithm for generating
algorithm for generating  -bit primes under GRH. In fact, Albert’s original idea (using intervals instead of arithmetic progressions) with the “win-win” twist also gives an
-bit primes under GRH. In fact, Albert’s original idea (using intervals instead of arithmetic progressions) with the “win-win” twist also gives an 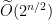 algorithm assuming RH. Further analysis is needed to see if the RH/GRH assumptions can be eliminated with a suitable choice of
algorithm assuming RH. Further analysis is needed to see if the RH/GRH assumptions can be eliminated with a suitable choice of 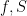 .
.
As a “proof of concept” experiment, I implemented the algorithm (without the win-win twist) to generate 1000-bit primes using only 121 random bits. (Specifically, I used the parity function together with the block design generated by cubic polynomials over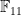 as described in the Nisan-Wigderson paper.) I didn’t try all
as described in the Nisan-Wigderson paper.) I didn’t try all  possible seeds, but I picked three random samples of 1000 seeds. The three runs gave me 4, 1, 5 primes. These agree with the expected 2.9 primes. The variance seems high, but I suspect that’s the price to pay for using 121 bits to do the work of 1000. Anyway, this doesn’t prove anything except for the fact that the idea is not fundamentally flawed.
possible seeds, but I picked three random samples of 1000 seeds. The three runs gave me 4, 1, 5 primes. These agree with the expected 2.9 primes. The variance seems high, but I suspect that’s the price to pay for using 121 bits to do the work of 1000. Anyway, this doesn’t prove anything except for the fact that the idea is not fundamentally flawed.
Comment by François Dorais — August 20, 2009 @ 8:57 am |
Beurling primes and integers
Tammy Ziegler gave me some very useful links to papers regarding Beurling numbers that contain some results and conjectures about them. Especially relevant is a paper by Jeff Lagarias. This is related to several aspects of our discussion.
We start with a collection of real numbers called B-primes and consider the ordered collection of all products,
and consider the ordered collection of all products,  . These products are referred to as B-integers.
. These products are referred to as B-integers.
For such systems you can talk about the "prime number theorem", "zeta function," "analytic continuation," "RH" and various statement about the gap distributions betweeb the primes (or related gaps between zeroes of the zeta function.) Beurling proved in the 30s the PNT under great generality is such cases.(What is needed is that the number of integers smaller than x is close enough to x.) For the stronger statements there are various counterexamples(Malliavin gave in the early 60s examples that satisfies known nice property of the zeta function and yet violate RH.).
Here are 2 basic examples for B-numbers
Example 1: The B-primes are the ordinary primes, the B-integers are the ordinary positive integers.
Example 2: The B-primes are of two types: a) primes which are 1 (mod 4) each with weight 2. b) Squares of primes which are 3(mod 4).
(The B-integers are those integers which can be expressed as the sum of 2 squares weighted by the number of such representations)
We come to Lagarias’s work:
The B-integers satisfies Delone property if for some r and R, the gaps are always bigger than r>0 and smaller than R.
are always bigger than r>0 and smaller than R.
Lagarias’s Conjecture 1: Beurling numbers with the Delone property satisfy (RH)
Lagarias’ Conjecture 2: Beurling numbers with the Delone property are obtained from the ordinary primes by deleting a finite number number of primes and adding certain sets of integers.
Lagarias proves
Conjecture 1Conjecture 2 for the case where the primes are integers and gave a complete characterization of such B-primes. [You mean Conjecture 2, right? – T.] [Yes, thnx]If Conjecture 2 is correct then Conjecture 1 is equivalent to the RH. Of course these conjectures seem very strong and looking for counter examples may be a good idea but nevertheless we can also try to consider even stronger conjectures.
Delone property also seems too strong (even example 2 is excluded) so lets us vaguely state:
“Strong Lagarias’ Conjecture:” Beurling integers with strong decay of gaps satisfy (RH).
Problem 1: Find (perhaps in the existing literature) an appealing form of “Strong Lagarias Conjecture”
Problem 2: What are the relations between the distribution of gaps for the B-integers and the distribution of gaps for the B-primes.
Problem 3 (in the anti razor razor direction): Will strong decay for the distribution of gaps for B-integers suffice to prove results about gaps of S-smooth numbers?
Challenge 4: Find stochastic models of Breuling primes for which the Breuling integers satisfies the conjectures on quick decay of gaps.
In the Delone case, Lagarias’s conjecture conflicts with such stochastic example (which is reasonable), but if we relax the Delong condition and try to immitate very closely the conjectured gap properties of primes maybe stochastic examples with nice properties of primes can be found.
I suppose that finding stochastic models for primes-like numbers is a big subject and I know very little about it.(I am aware of a book by Arratia, Barbour and Tavare on probabilistic approach to logarithmic combinatorial structures. (but did not read it).)
Example 3: Consider a random subset of primes, each prime is taken with probability 1/2 and each taken prime is given a weight 2. I do not know if this example (or some other weighted version) satisfies (RH). I remember I was told that without the weights you do not have even analytic continuation but I do not have a link for this result.
We can formulate our algorithmic problem for general Beurling prime systems. Suppose that we have a cost 1 oracle to access the $n$th B-integer, and to check for B-primality and (possibly) to B-factor, how many steps are needed to find a prime number greater than the nth B-integer.
There are various papers by Titus Hilberdink and coauthors with all sort of amazing connections to various other areas, and Tammy also mentioned a recent Mertens’ formula by Ricard Ollofson.
Comment by Gil Kalai — August 18, 2009 @ 1:21 pm |
Regarding the “strong Lagarias conjecture” it can be perhaps more narural to try to relate the gaps between the “square free Beurling numbers” and the gaps between the “primes”. I.e. to try to relate to conjectured behavior of gaps between primes (or for zeroes of zeta function) to the conjectured behavior of gaps between squere free numbers (is the later conjectured to be Poisson? are squere freeness like coin flips?) hoping that for some stochatics models the connection be easier. Maybe the relation between gaps of square free numbers and between gaps of primes a standard issue? are there standard conjectures (theorems??) about it?
Another cute thought is to understand the Beurling “transform” from “primes” to “integers” for continuous measures. (Start with a measure mu supported on [2,infinity] and consider the sum of mu mu*mu mu*mu*mu etc.) From Ollofson’s paper I realize that Beurling himself already studied it but I wonder what is known about it.
Comment by Gil — August 21, 2009 @ 11:13 am |
[…] generate a prime number of at least digits. The post isn’t a contribution to the ongoing research discussion, but rather describes background material I wanted to understand better: a proof of a mathematical […]
Pingback by Michael Nielsen » Bertrand’s postulate — August 18, 2009 @ 1:53 pm |
I was thinking a little about the toy problem of how to estimate the sum in time
in time  rather than
rather than 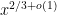 . To simplify matters I looked at the model case where a, b are restricted to be comparable to
. To simplify matters I looked at the model case where a, b are restricted to be comparable to  , say
, say  . Then one is counting the lattice points under the curve
. Then one is counting the lattice points under the curve 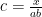 . The naive algorithm of summing
. The naive algorithm of summing  for
for  is clearly a
is clearly a 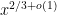 algorithm.
algorithm.
It seems to me that it would suffice to understand how to count lattice points under curves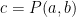 for
for  , where P is a polynomial of bounded degree that takes values comparable to
, where P is a polynomial of bounded degree that takes values comparable to  on this square. The point is that by subdividing the a,b square into subsquares of length
on this square. The point is that by subdividing the a,b square into subsquares of length 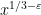 for some
for some 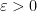 , and then Taylor expanding
, and then Taylor expanding  on each subsquare up to accuracy
on each subsquare up to accuracy 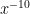 (say), one can reduce things to the polynomial problem. (The
(say), one can reduce things to the polynomial problem. (The 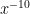 error can be eliminated by noting from the divisor bound that there are only
error can be eliminated by noting from the divisor bound that there are only  lattice points on the curve
lattice points on the curve  , and all the other lattice points lie a distance at least
, and all the other lattice points lie a distance at least  away (since the denominator ab has size about
away (since the denominator ab has size about  ), so one just has to manually correct for
), so one just has to manually correct for  lattice points by checking whether they lie under the Taylor approximant or not.)
lattice points by checking whether they lie under the Taylor approximant or not.)
In the special case when the polynomial P decouples as , it seems like an FFT is a possibility. The idea is to round off Q and R to the nearest integer, and convolve the images of Q and R using an FFT. In principle this only requires
, it seems like an FFT is a possibility. The idea is to round off Q and R to the nearest integer, and convolve the images of Q and R using an FFT. In principle this only requires  time. Unfortunately the rounding occasionally runs into “carry” issues. Since we cannot afford to count even a single lattice point incorrectly in this strategy, one has to fight harder to deal with this issue; one can add more precision but this degrades the run time. Admittedly there is a bit of room between
time. Unfortunately the rounding occasionally runs into “carry” issues. Since we cannot afford to count even a single lattice point incorrectly in this strategy, one has to fight harder to deal with this issue; one can add more precision but this degrades the run time. Admittedly there is a bit of room between  and
and  so perhaps this can be salvaged.
so perhaps this can be salvaged.
Perhaps rewriting as
as 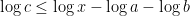 may allow FFT methods to be used? Again one is running into the problem though that more precision is needed. (Also, the Fourier transform of the log-integers is close to the zeta function, so we may just be rehashing old Strategy A options here.)
may allow FFT methods to be used? Again one is running into the problem though that more precision is needed. (Also, the Fourier transform of the log-integers is close to the zeta function, so we may just be rehashing old Strategy A options here.)
Comment by Terence Tao — August 18, 2009 @ 8:53 pm |
I had a few thoughts about the finding consecutive squarefree ingegers problem today.
First an elementary observation. The problem is equivalent to finding a large squarefree value of the quadratic polynomial (simply by the relation
(simply by the relation  ). (Also I think, modulo some congruence conditions, the problem is also equivalent to finding squarefree solutions to the polynomial
). (Also I think, modulo some congruence conditions, the problem is also equivalent to finding squarefree solutions to the polynomial  ).
).
Secondly, it would be nice to obtain unconditional results in the direction of this problem (without a factoring oracle). Related to this there is a paper of Lenstra (“Miller’s Primality Test”) in which he gives a polynomial-time deterministic test that identifies squarefree numbers (the problem is that it might fail to report a squarefree number). The algorithm is fairly simple: If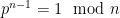 for every prime
for every prime  such that
such that 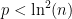 then
then  is square-free.
is square-free.
Some possible directions to go with this would be to (1) try to understand the exceptional set of "pseduo-squarefree numbers", and show our current algorithms work using this test (2) try to prove that some variant can always detect squarefree numbers, possibly assuming some number theoretic conjecture (such as GRH), that is find a Miller-Rabin-type test, and (3) try to apply the ideas of AKS to get a polynomial-time deterministic test without error.
Comment by Mark Lewko — August 19, 2009 @ 12:04 am |
Looking at the results of Eric Bach [Explicit bounds for primality testing and related problems, Math. Comp. 55 (1990), 355-380], I think that replacing by
by  in Lenstra’s test turns it into a “Carmichaelity” test under ERH. So I suppose that very few squarefree numbers pass this test.
in Lenstra’s test turns it into a “Carmichaelity” test under ERH. So I suppose that very few squarefree numbers pass this test.
Comment by François Dorais — August 19, 2009 @ 12:50 am |
I have a small remark on Croot’s strategy (post #12). Let me briefly summarize the strategy. In his post Croot showed how to compute the parity of in
in  steps. It has also been observed that if we can compute
steps. It has also been observed that if we can compute  for all
for all  then we can recover
then we can recover  exactly. We could then use a binary search to find a prime near
exactly. We could then use a binary search to find a prime near  in around
in around  steps. The difficulty with this, so far at least, is that we haven’t been able to compute
steps. The difficulty with this, so far at least, is that we haven’t been able to compute  in fewer than
in fewer than  steps. The hope is that we could compute all of
steps. The hope is that we could compute all of 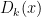 (for
(for  in time
in time 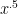 and thus compute
and thus compute  in around
in around 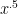 steps. We could then find a prime a large prime using a binary search, in around
steps. We could then find a prime a large prime using a binary search, in around 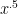 steps.
steps.
It seems to me that if we succeed in this strategy we not only will be able to find some digit prime in around
digit prime in around 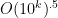 steps, but we will also have have solved a much more general problem: we'll be able to compute the
steps, but we will also have have solved a much more general problem: we'll be able to compute the  -th prime in around
-th prime in around 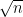 steps. By the prime number theorem we know that the
steps. By the prime number theorem we know that the  -th prime is between
-th prime is between ![[0, c n\ln(n)]](https://s0.wp.com/latex.php?latex=%5B0%2C+c+n%5Cln%28n%29%5D&bg=ffffff&fg=000000&s=0&c=20201002) , we'll then should be able to locate it using in a binary search (querying
, we'll then should be able to locate it using in a binary search (querying  at each stage) in around
at each stage) in around  steps (ignoring logs).
steps (ignoring logs).
I don't have any particular reason to think that this shouldn't be possible. However, the fact that it would solve a much more general problem is cause for thought.
Comment by Mark Lewko — August 20, 2009 @ 3:43 am |
If we can find a fast algorithm to solve these lattice counting problems, I think we should be able to use it in sympathy with the prime gap results.
Let’s assume RH. We then have that there is a prime in the interval![[x, x+ x^{1/2}]](https://s0.wp.com/latex.php?latex=%5Bx%2C+x%2B+x%5E%7B1%2F2%7D%5D&bg=ffffff&fg=000000&s=0&c=20201002) (I’m going to ignore logs throughout this). Now to find this prime using a binary search we could compute
(I’m going to ignore logs throughout this). Now to find this prime using a binary search we could compute  for various values of
for various values of 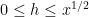 . However, this is really more information than we need. It would suffice to know
. However, this is really more information than we need. It would suffice to know  for these values of
for these values of  .
.
Using Linnik’s identity, to find (or, more precisely
(or, more precisely  ) all we need to know is
) all we need to know is  for
for  . In the
. In the  case, this is
case, this is  . Now if
. Now if  , we should be able to compute this in about
, we should be able to compute this in about  steps. (Similarly, I think we should be able to compute the parity of
steps. (Similarly, I think we should be able to compute the parity of  in
in  steps. )
steps. )
Now if we can find a way to compute all of the in
in  steps (
steps ( is the trivial mark here), I think, it will get is below
is the trivial mark here), I think, it will get is below 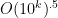 . I think a modification to my calculations above (August 18, 2009 @ 12:26 am) gives that
. I think a modification to my calculations above (August 18, 2009 @ 12:26 am) gives that  is computable in
is computable in 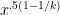 steps, but this isn’t bounded away from
steps, but this isn’t bounded away from 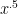 for large
for large  .
.
Similar remarks should hold starting with the Baker-Harmen unconditional prime gap result instead of RH.
Comment by Mark Lewko — August 21, 2009 @ 8:30 am |
Here are some comments on the “parity of pi” approach (I had a little free time yesterday!):
1. By generalizing the approach in just the right way, one can develop a completely different way to locate primes, that does not involve the prime counting function. The idea is to work in the polynomial ring![F_2[x]](https://s0.wp.com/latex.php?latex=F_2%5Bx%5D&bg=ffffff&fg=000000&s=0&c=20201002) instead of just
instead of just  : I think one can compute the prime generating function
: I think one can compute the prime generating function
in![F_2[x]](https://s0.wp.com/latex.php?latex=F_2%5Bx%5D&bg=ffffff&fg=000000&s=0&c=20201002) using the same approach as finding the parity of
using the same approach as finding the parity of  . Of course, because
. Of course, because 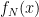 has
has 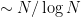 terms, by itself it is useless; HOWEVER, if one is given a polynomial
terms, by itself it is useless; HOWEVER, if one is given a polynomial  , of degree less than
, of degree less than  , say, then I think one should be able to compute
, say, then I think one should be able to compute  in time only slightly worse than
in time only slightly worse than  . The reason is that the polynomial
. The reason is that the polynomial 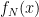 has a “short description” — it looks something like
has a “short description” — it looks something like
for carefully chosen . Of course that isn’t quite right, because as we know, computing
. Of course that isn’t quite right, because as we know, computing 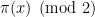 is done recursively — this is only the first step in the recursion.
is done recursively — this is only the first step in the recursion.
Ok, so to show that there is a prime number in some interval![[M,N]](https://s0.wp.com/latex.php?latex=%5BM%2CN%5D&bg=ffffff&fg=000000&s=0&c=20201002) , all we have to do is present a polynomial
, all we have to do is present a polynomial  (preferably very low degree) such that $g(x)$ does NOT divide
(preferably very low degree) such that $g(x)$ does NOT divide  in
in ![F_2[x]](https://s0.wp.com/latex.php?latex=F_2%5Bx%5D&bg=ffffff&fg=000000&s=0&c=20201002) . It seems to me that in order to have a chance of making this method work, one will need an explicit form for the generating function
. It seems to me that in order to have a chance of making this method work, one will need an explicit form for the generating function 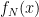 , similar to the approximate formula above, except that perhaps some of the coefficients of the
, similar to the approximate formula above, except that perhaps some of the coefficients of the 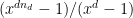 are not 1 (maybe they will be binomial coefficients or something, like in Mark Lewko’s nice formulas). Note that this method will tell us nothing about the prime counting function, so it is a completely different type of approach than the parity-of-pi method.
are not 1 (maybe they will be binomial coefficients or something, like in Mark Lewko’s nice formulas). Note that this method will tell us nothing about the prime counting function, so it is a completely different type of approach than the parity-of-pi method.
How could we locate a non-divisor ? Here are some suggestions:
? Here are some suggestions:
A. Maybe there is a way to rapidly determine the power that a single polynomial divides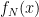 . If so, then we could just attempt to show that
. If so, then we could just attempt to show that 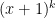 fails to divide our polynomial for some
fails to divide our polynomial for some  .
.
B. One can manipulate the function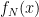 a little, to determine the generating function for the number of number of integers in
a little, to determine the generating function for the number of number of integers in ![[1,N]](https://s0.wp.com/latex.php?latex=%5B1%2CN%5D&bg=ffffff&fg=000000&s=0&c=20201002) that are multiples of some small primes, and then one very large prime. For our purposes, that is all we need to locate a large prime, since we could recover it by doing some factoring. The fact that such a manipulation to the generating function of
that are multiples of some small primes, and then one very large prime. For our purposes, that is all we need to locate a large prime, since we could recover it by doing some factoring. The fact that such a manipulation to the generating function of 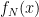 is the sort we have easy control over, it seems plausible that through some combination of looking for small degree polynomial divisors and such adjustments to our generating function, we could locate a low-degree non-divisor.
is the sort we have easy control over, it seems plausible that through some combination of looking for small degree polynomial divisors and such adjustments to our generating function, we could locate a low-degree non-divisor.
C. We don’t just have to work with the function to locate primes — we can also work with Jacobi or Kronecker symbols. In other words, we can work with
to locate primes — we can also work with Jacobi or Kronecker symbols. In other words, we can work with 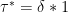 , where
, where  . I think when we do this, after the dust has settled, we will be able to find the parity of the number of primes
. I think when we do this, after the dust has settled, we will be able to find the parity of the number of primes  that are squares mod q (well, for q prime); and in the context of the polynomial method above, we will be able to locate primes that are squares mod q, q prime. Now, when we go to working with Kronecker symbols, it seems to me that this will only require minor adjustments to our generating function formula — adjustments that we can get our hands on, and hopefully show that some adjustment leaves us with a polynomial not divisible by a certain low-degree polynomial.
that are squares mod q (well, for q prime); and in the context of the polynomial method above, we will be able to locate primes that are squares mod q, q prime. Now, when we go to working with Kronecker symbols, it seems to me that this will only require minor adjustments to our generating function formula — adjustments that we can get our hands on, and hopefully show that some adjustment leaves us with a polynomial not divisible by a certain low-degree polynomial.
2. The other comment I wanted to make concerns the function that we were trying to count before. We were trying to do this to determine the prime counting function mod 3. Well, there are other ways to find
that we were trying to count before. We were trying to do this to determine the prime counting function mod 3. Well, there are other ways to find  mod 3 that might be easier — I haven’t spent much time thinking about it, but here goes: let
mod 3 that might be easier — I haven’t spent much time thinking about it, but here goes: let  be a non-principal, cubic Dirichlet character mod 7. Then define the multiplicative function
be a non-principal, cubic Dirichlet character mod 7. Then define the multiplicative function  . If
. If  is square-free, and not divisible by 7, then I think that
is square-free, and not divisible by 7, then I think that  is non-zero precisely when
is non-zero precisely when  is a prime that is 1 or -1 mod 7. By taking other kinds of convolution here, I think one can tell whether n is in other cosets of the index-3 multiplicative subgroup
is a prime that is 1 or -1 mod 7. By taking other kinds of convolution here, I think one can tell whether n is in other cosets of the index-3 multiplicative subgroup  . So, it seems to me that by counting sums like
. So, it seems to me that by counting sums like 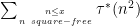 , one can determine
, one can determine 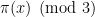 .
.
Of course, this approach has its own drawbacks: One *does* have a kind of hyperbola method here to compute such sums, but the fact that we work with , instead of
, instead of  , means that there are too many terms to sort through, to give a
, means that there are too many terms to sort through, to give a  algorithm. Well, that is just what I surmised by a back-of-the envelope calculation — maybe there are smarter ways to compute the sum.
algorithm. Well, that is just what I surmised by a back-of-the envelope calculation — maybe there are smarter ways to compute the sum.
Later today I will try to think about the incidence geometry approach I wrote about earlier this week (Szemeredi-Trotter), and will write about it either today or tomorrow if it works out…
Comment by Ernie Croot — August 22, 2009 @ 3:00 pm |
On the discussion thread, we discovered that a method of Odlyzko lets us deterministically find k-digit primes in time without RH (i.e. solving Problem 2); I wrote up the method at
without RH (i.e. solving Problem 2); I wrote up the method at
http://michaelnielsen.org/polymath1/index.php?title=Odlyzko%27s_method
There is also a combinatorial method (the Meissel-Lehmer method) that gives a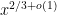 algorithm,
algorithm,
Click to access meissel.lehmer.pdf
The bottleneck in the Odlyzko method is that it takes about time and space to compute the number of primes in
time and space to compute the number of primes in ![[x-y,x]](https://s0.wp.com/latex.php?latex=%5Bx-y%2Cx%5D&bg=ffffff&fg=000000&s=0&c=20201002) for
for  close to
close to  (by sieve of Eratosthenes). If, for instance, one could compute the number of primes in
(by sieve of Eratosthenes). If, for instance, one could compute the number of primes in ![[x-x^{0.501},x]](https://s0.wp.com/latex.php?latex=%5Bx-x%5E%7B0.501%7D%2Cx%5D&bg=ffffff&fg=000000&s=0&c=20201002) in time
in time  , then Odlyzko’s method would give a
, then Odlyzko’s method would give a  algorithm.
algorithm.
Comment by Terence Tao — August 22, 2009 @ 6:01 pm |
Alternatively: Odlyzko’s method lets us deterministically zoom in (in time) on an interval of size
time) on an interval of size  which is guaranteed to contain a prime (in fact, by pigeonhole one can ensure that the density of primes here is at least
which is guaranteed to contain a prime (in fact, by pigeonhole one can ensure that the density of primes here is at least  ). But we don’t yet know how to actually extract a prime from this interval yet in anything better than
). But we don’t yet know how to actually extract a prime from this interval yet in anything better than  time.
time.
Comment by Terence Tao — August 22, 2009 @ 6:05 pm |
I wrote up a sketch of the Meissel-Lehmer method at
http://michaelnielsen.org/polymath1/index.php?title=Meissel-Lehmer_method
There are a number of bottlenecks preventing this method from going past x^{2/3}. One of them is to compute the sum \sum_{x^{1/3} < p,q < x^{2/3}: pq < x} 1, where p, q range over primes. I don’t see a way to do this in time faster than x^{2/3}.
Comment by Terence Tao — August 22, 2009 @ 6:38 pm |
Looking at this problem from the other direction I wonder, how long prime-free intervals can be explicitly constructed?
That is, without simply testing all integers up to some size, and assuming some upper bound for the integers considered.
Comment by Klas Markström — August 23, 2009 @ 12:47 pm |
Well, the example of the prime-free intervals![[p!+2;p!+p]](https://s0.wp.com/latex.php?latex=%5Bp%21%2B2%3Bp%21%2Bp%5D&bg=ffffff&fg=000000&s=0&c=20201002) has been mentionned by Gil already I think. Wikipedia remarks that in fact
has been mentionned by Gil already I think. Wikipedia remarks that in fact ![[p!+2;p!+q]](https://s0.wp.com/latex.php?latex=%5Bp%21%2B2%3Bp%21%2Bq%5D&bg=ffffff&fg=000000&s=0&c=20201002) is prime-free, where
is prime-free, where  is the prime following
is the prime following  .
.
Maybe we can push this example: it seems to me that for any integer the intervals
the intervals ![[k\cdot p!+2; k\cdot p!+p]](https://s0.wp.com/latex.php?latex=%5Bk%5Ccdot+p%21%2B2%3B+k%5Ccdot+p%21%2Bp%5D&bg=ffffff&fg=000000&s=0&c=20201002) are also prime-free (since
are also prime-free (since  is also divisible by 2,
is also divisible by 2,  by 3 and so on). For instance in the case
by 3 and so on). For instance in the case  it leads to pairs of non-primes spaced by
it leads to pairs of non-primes spaced by  , namely
, namely ![[8,9]](https://s0.wp.com/latex.php?latex=%5B8%2C9%5D&bg=ffffff&fg=000000&s=0&c=20201002) ,
, ![[14,15]](https://s0.wp.com/latex.php?latex=%5B14%2C15%5D&bg=ffffff&fg=000000&s=0&c=20201002) … which is a kind of block-sieve maybe. The way various intervals are removed (and overlap) for different primes
… which is a kind of block-sieve maybe. The way various intervals are removed (and overlap) for different primes  is probably non-trivial, I’ll try to get some numerics.
is probably non-trivial, I’ll try to get some numerics.
Comment by Thomas Sauvaget — August 23, 2009 @ 3:08 pm |
If this theorem is not true then we simply construct a number and it is surrounded by a large prime free interval(if k is the number of digits then we can pick a number say 100 and the interval is of size at least k^100. So if this theorem were not true then the only cost would constructing the number and that would be relatively cheap.
Comment by Kristal Cantwell — August 23, 2009 @ 6:34 pm |
Since the larger context of our problem is to find relations between computational complexity problems (and hierarchies of conjectures) and number theoretic problems (and hierarchies of conjectures) let’s try to examine the following heuristic (vaguely stated)suggestion:
(PIR) “Every problem which is computationally easy for integers is also computationally easy for primes.”
For example: finding the smallest integer larger than an integer x is easy, and by Cramer’s conjecture so is finding the smallest prime larger than x. Is there an integer in the interval![[\alpha,\beta]](https://s0.wp.com/latex.php?latex=%5B%5Calpha%2C%5Cbeta%5D&bg=ffffff&fg=000000&s=0&c=20201002) is easy so (PIR) suggests that so is answering the question “Is there a prime in the above interval?”. (Again this is true under Cramer.)
is easy so (PIR) suggests that so is answering the question “Is there a prime in the above interval?”. (Again this is true under Cramer.)
“Is there an integral vector satisfying a a system of inequalities?” is known to be an easy question when the number of variables is bounded, and (PIR) asserts that so is the question about such vectors with all-prime-coordinates. If it is easy to determine if a certain Diophantine equation has integer solution in a certain range then it should also be easy to determine if it has prime solution, etc.
Maybe (PIR) is silly and admits simple counterexamples but I cannot think of any.
(Unlike deterministically finding primes the issue here is not derandomization.) The reverse principle seems untrue since factoring is easy for primes and apparently hard for integers.(And so is the question if an integer is the sum of 2 squares.)
Comment by Gil Kalai — August 23, 2009 @ 9:18 pm |
Presumably one has to narrow the set of problems to the “interesting” ones to avoid grue paradoxes. For instance, if one defines a grue number to be a number which is either composite, or is the n^th prime where n is the Godel number of a proof of an undecidable statement, then finding a grue integer is trivial but finding a grue prime is undecidable.
Of course, the artificiality here came from the fact that primality was used to define the notion of a grue number. I suppose if one avoided using primality or other number-theoretic notions in defining the problem at hand, then one could perhaps get somewhere. If the primes were sufficiently computationally pseudorandom then I guess any low-complexity problem could not distinguish between primes and integers (by definition of computational pseudorandomness) and so this might be a formalisable version of the principle.
Comment by Terence Tao — August 24, 2009 @ 1:46 am |
It’s also very easy to decide whether there is an integral solution to in a given range. I’d be quite interested in an algorithm that could find prime solutions …
in a given range. I’d be quite interested in an algorithm that could find prime solutions …
Comment by gowers — August 24, 2009 @ 9:13 am |
Right, if we want to propose formal version rather than a heuristics, we will need to talk about low complexity problems. Even for them this heuristics represents a vastly strong conjecture on primes being pesudorandom. (So strong, that maybe there is a “real” counterexample – something which is easy for integers and hard for primes like factoring is in the other direction).
In particular, finding twin primes in an interval has (based on what we conjecture about primes) a polynomial-time algorithm because if the interval is large the algorithm just say YES, (relying on a strong version of Cramer’s conjecture), and if the interval is small it checks all numbers there.
Comment by Gil Kalai — August 24, 2009 @ 11:23 am |
Actually, I do not know if such a principle holds even when you replace the primes by, say, a truly random subset of the integers (say of density 1/2).
Comment by Gil — August 24, 2009 @ 2:10 pm |
I believe you can modify Lenstra’s algorithm for integer linear programming to get a probabilistic algorithm for “random subset of the integers linear programming” by randomly sampling the lower-dimensional slices in the recursive step. The density of the random subset will clearly affect the required number of samples and thus the running time.
Applied to prime numbers, the algorithm’s strategy for finding primes in an interval would just reduce to randomly sampling integers in the interval and checking primality. Same goes for what the algorithm would do to find twin primes. Is anything is known about random sampling and twin primes?
Comment by Nicolai Hähnle — August 28, 2009 @ 1:33 pm |
This is interesting. I suppose the conjecture would be that a random k-digit number is a young twin prime with probability k^{-2}; but this just like Cramer’s conjecture are well well beyond reach.
So for integer programming in bounded dimension when the random subset is of density 1/2, does your argument gives average polynomial running time or even O(poly) running time almost surely. And what precisely the random sampling statement for primes you would need to extend it?
I suppose the next problem to play with is Frobenius coin problem. Ravi Kannan proved that there is a polynomial algorithm to determine the largest amount you canot pay with relatively prime k coins. We want to say that we can also determine the largest integer in a random subset of integers (or the largest prime) that we cannot pay. This does not look automatic from the problem but maybe follows from Kannan’s algorithm.
Comment by Gil Kalai — August 29, 2009 @ 9:01 am |
Here is an idea for how to cross the square-root barrier (and possibly even compute the parity of pi in sub-exponential time), which is perhaps similar to Terry’s strategy: at the top level in two of the “parity of pi approaches” (the
strategy: at the top level in two of the “parity of pi approaches” (the 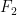 and the
and the ![F_2[x]](https://s0.wp.com/latex.php?latex=F_2%5Bx%5D&bg=ffffff&fg=000000&s=0&c=20201002) approaches I wrote about), we must compute sums
approaches I wrote about), we must compute sums  mod 2. I believe this can be facilitated by applying the following basic identity
mod 2. I believe this can be facilitated by applying the following basic identity
(I suppose one can think of it as some type of 2D Taylor/Laurent expansion, as in Terry’s approach, but I prefer to just think of it as some polynomial arithmetic.)
approach, but I prefer to just think of it as some polynomial arithmetic.)
as I will explain; and, of course there are identities involving many more terms of this sort — relating to
to  , for some k.
, for some k.
Now the way this can be used is as follows: our sum-of-tau can be expressed in terms of the sum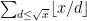 , and let us consider the contribution of those
, and let us consider the contribution of those ![d \in [x^{1/3+\epsilon}, x^{1/2}]](https://s0.wp.com/latex.php?latex=d+%5Cin+%5Bx%5E%7B1%2F3%2B%5Cepsilon%7D%2C+x%5E%7B1%2F2%7D%5D&bg=ffffff&fg=000000&s=0&c=20201002) : first, note that applying the above identity we have that for any such d and for
: first, note that applying the above identity we have that for any such d and for 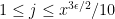 , say, we have that
, say, we have that
where or so, we just have to look up in the table the entry corresponding to which of our mod 2 intervals
or so, we just have to look up in the table the entry corresponding to which of our mod 2 intervals  and
and  happen to lie in.
happen to lie in.
This clearly can all be done in time substantially less than , as it doesn’t take that long to build the table, at least if
, as it doesn’t take that long to build the table, at least if 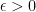 isn’t too big. Also, here is a way to deal with the issue of mod 2 carries: first of all, they occur only very rarely, and in building the
isn’t too big. Also, here is a way to deal with the issue of mod 2 carries: first of all, they occur only very rarely, and in building the  table, we can add data indicating exactly where they can occur given the initial data
table, we can add data indicating exactly where they can occur given the initial data  — in this way we can know where to be more careful about them.
— in this way we can know where to be more careful about them.
Ok, so that is a crude first step to how to beat the square-root barrier. Now, what *should* probably be the case is that there is some very quick algorithm that determines the number of terms in the sequence that round down to an odd number, given
that round down to an odd number, given  . And furthermore, there should be an equally simple algorithm that works with more terms — i.e. the natural extension of the above where we relate
. And furthermore, there should be an equally simple algorithm that works with more terms — i.e. the natural extension of the above where we relate  to
to  . If this is so, then my calculations indicate that the parity of the sum
. If this is so, then my calculations indicate that the parity of the sum 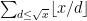 should be computable in sub-exponential time.
should be computable in sub-exponential time.
That wouldn’t give us a sub-exponential time to compute the parity of just yet, though, because there are still around
just yet, though, because there are still around  levels of iteration to consider. But I think that once one unrolls these iterations, and expresses
levels of iteration to consider. But I think that once one unrolls these iterations, and expresses  in terms of linear combinations of sums of divisor functions, one might have a chance to evaluate the parity of these quickly enough (perhaps through heavy use of Kummer’s Theorem on p-divisiblity of binomial coefficients, with p = 2) to beat the square-root barrier, and possibly even get a sub-exponential time algorithm. If this is so, then I think there is a good chance that a similar idea will work with the
in terms of linear combinations of sums of divisor functions, one might have a chance to evaluate the parity of these quickly enough (perhaps through heavy use of Kummer’s Theorem on p-divisiblity of binomial coefficients, with p = 2) to beat the square-root barrier, and possibly even get a sub-exponential time algorithm. If this is so, then I think there is a good chance that a similar idea will work with the ![F_2[x]](https://s0.wp.com/latex.php?latex=F_2%5Bx%5D&bg=ffffff&fg=000000&s=0&c=20201002) algorithm I mentioned in a previous posting because, after all, modding the prime generating function out by the polynomial
algorithm I mentioned in a previous posting because, after all, modding the prime generating function out by the polynomial  in
in ![F_2[x]](https://s0.wp.com/latex.php?latex=F_2%5Bx%5D&bg=ffffff&fg=000000&s=0&c=20201002) is equivalent to determining the parity of
is equivalent to determining the parity of  , and one wouldn’t expect that it should be any harder for other low-degree polynomials.
, and one wouldn’t expect that it should be any harder for other low-degree polynomials.
Comment by Ernie Croot — August 24, 2009 @ 1:19 am |
Some of what I wrote seems to be missing from the above posting — maybe it is an error with wordpress. Here is the stuff below where the error E is introduced:
where or so, we just have to look up in the table the entry corresponding to which of our mod 2 intervals
or so, we just have to look up in the table the entry corresponding to which of our mod 2 intervals  and
and  happen to lie in.
happen to lie in.
This clearly can all be done in time substantially less than , as it doesn’t take that long to build the table, at least if
, as it doesn’t take that long to build the table, at least if 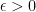 isn’t too big. Also, here is a way to deal with the issue of mod 2 carries: first of all, they occur only very rarely, and in building the
isn’t too big. Also, here is a way to deal with the issue of mod 2 carries: first of all, they occur only very rarely, and in building the  table, we can add data indicating exactly where they can occur given the initial data
table, we can add data indicating exactly where they can occur given the initial data  — in this way we can know where to be more careful about them.
— in this way we can know where to be more careful about them.
Ok, so that is a crude first step to how to beat the square-root barrier. Now, what *should* probably be the case is that there is some very quick algorithm that determines the number of terms in the sequence that round down to an odd number, given
that round down to an odd number, given  . And furthermore, there should be an equally simple algorithm that works with more terms — i.e. the natural extension of the above where we relate
. And furthermore, there should be an equally simple algorithm that works with more terms — i.e. the natural extension of the above where we relate  to
to  . If this is so, then my calculations indicate that the parity of the sum
. If this is so, then my calculations indicate that the parity of the sum 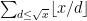 should be computable in sub-exponential time.
should be computable in sub-exponential time.
That wouldn’t give us a sub-exponential time to compute the parity of just yet, though, because there are still around
just yet, though, because there are still around  levels of iteration to consider. But I think that once one unrolls these iterations, and expresses
levels of iteration to consider. But I think that once one unrolls these iterations, and expresses  in terms of linear combinations of sums of divisor functions, one might have a chance to evaluate the parity of these quickly enough (perhaps through heavy use of Kummer’s Theorem on p-divisiblity of binomial coefficients, with p = 2) to beat the square-root barrier, and possibly even get a sub-exponential time algorithm. If this is so, then I think there is a good chance that a similar idea will work with the
in terms of linear combinations of sums of divisor functions, one might have a chance to evaluate the parity of these quickly enough (perhaps through heavy use of Kummer’s Theorem on p-divisiblity of binomial coefficients, with p = 2) to beat the square-root barrier, and possibly even get a sub-exponential time algorithm. If this is so, then I think there is a good chance that a similar idea will work with the ![F_2[x]](https://s0.wp.com/latex.php?latex=F_2%5Bx%5D&bg=ffffff&fg=000000&s=0&c=20201002) algorithm I mentioned in a previous posting because, after all, modding the prime generating function out by the polynomial
algorithm I mentioned in a previous posting because, after all, modding the prime generating function out by the polynomial  in
in ![F_2[x]](https://s0.wp.com/latex.php?latex=F_2%5Bx%5D&bg=ffffff&fg=000000&s=0&c=20201002) is equivalent to determining the parity of
is equivalent to determining the parity of  , and one wouldn’t expect that it should be any harder for other low-degree polynomials.
, and one wouldn’t expect that it should be any harder for other low-degree polynomials.
Comment by Ernie Croot — August 24, 2009 @ 1:25 am |
Ok, WordPress did it again. Here is one last attempt, following a slight rewording:
where $E$ at most 1/10 or so. Modding both sides out by 2 (we are working here with , not
, not 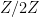 ) we get
) we get
and so, if we knew the values of and
and 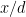 mod 2, then to within a good error, we can easily determine the value of
mod 2, then to within a good error, we can easily determine the value of  mod 2. The upshot of this is that, forgetting the issue of wraparound mod 2 (e.g. the number 1.01 is within 1/10 of 0.99, yet 1.01 rounds down to 1 which is odd while 0.99 rounds down to 0 which is even — this issue surely can be dealt with easily), given these two initial values we should be able to quickly determine the parity of the numbers
mod 2. The upshot of this is that, forgetting the issue of wraparound mod 2 (e.g. the number 1.01 is within 1/10 of 0.99, yet 1.01 rounds down to 1 which is odd while 0.99 rounds down to 0 which is even — this issue surely can be dealt with easily), given these two initial values we should be able to quickly determine the parity of the numbers  for
for 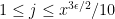 , thereby speeding up our sum-of-divisors-mod-2 calculation considerably.
, thereby speeding up our sum-of-divisors-mod-2 calculation considerably.
Well, here is a crude way to do this: subdivide the interval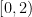 up into a say
up into a say 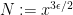 or so sub-intevals. Then, build an
or so sub-intevals. Then, build an  table, whose
table, whose  entry counts the parity of the number of terms in the sequence
entry counts the parity of the number of terms in the sequence 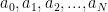 that round down to an odd number, where the sequence is generated as follows: let
that round down to an odd number, where the sequence is generated as follows: let 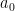 be the center point of the hth interval, and let
be the center point of the hth interval, and let 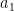 be the center point of the ith interval. Then, let
be the center point of the ith interval. Then, let 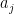 be produced through the relation
be produced through the relation
One can build this table in time at most . Then, to determine the parity of a short piece like
. Then, to determine the parity of a short piece like 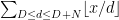 , where
, where 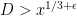 or so, we just have to look up in the table the entry corresponding to which of our mod 2 intervals
or so, we just have to look up in the table the entry corresponding to which of our mod 2 intervals  and
and  happen to lie in.
happen to lie in.
This clearly can all be done in time substantially less than , as it doesn’t take that long to build the table, at least if
, as it doesn’t take that long to build the table, at least if 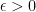 isn’t too big. Also, here is a way to deal with the issue of mod 2 carries: first of all, they occur only very rarely, and in building the
isn’t too big. Also, here is a way to deal with the issue of mod 2 carries: first of all, they occur only very rarely, and in building the  table, we can add data indicating exactly where they can occur given the initial data
table, we can add data indicating exactly where they can occur given the initial data  — in this way we can know where to be more careful about them.
— in this way we can know where to be more careful about them.
Ok, so that is a crude first step to how to beat the square-root barrier. Now, what *should* probably be the case is that there is some very quick algorithm that determines the number of terms in the sequence that round down to an odd number, given
that round down to an odd number, given  . And furthermore, there should be an equally simple algorithm that works with more terms — i.e. the natural extension of the above where we relate
. And furthermore, there should be an equally simple algorithm that works with more terms — i.e. the natural extension of the above where we relate  to
to  . If this is so, then my calculations indicate that the parity of the sum
. If this is so, then my calculations indicate that the parity of the sum 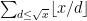 should be computable in sub-exponential time.
should be computable in sub-exponential time.
That wouldn’t give us a sub-exponential time to compute the parity of just yet, though, because there are still around
just yet, though, because there are still around  levels of iteration to consider. But I think that once one unrolls these iterations, and expresses
levels of iteration to consider. But I think that once one unrolls these iterations, and expresses  in terms of linear combinations of sums of divisor functions, one might have a chance to evaluate the parity of these quickly enough (perhaps through heavy use of Kummer’s Theorem on p-divisiblity of binomial coefficients, with p = 2) to beat the square-root barrier, and possibly even get a sub-exponential time algorithm. If this is so, then I think there is a good chance that a similar idea will work with the
in terms of linear combinations of sums of divisor functions, one might have a chance to evaluate the parity of these quickly enough (perhaps through heavy use of Kummer’s Theorem on p-divisiblity of binomial coefficients, with p = 2) to beat the square-root barrier, and possibly even get a sub-exponential time algorithm. If this is so, then I think there is a good chance that a similar idea will work with the ![F_2[x]](https://s0.wp.com/latex.php?latex=F_2%5Bx%5D&bg=ffffff&fg=000000&s=0&c=20201002) algorithm I mentioned in a previous posting because, after all, modding the prime generating function out by the polynomial
algorithm I mentioned in a previous posting because, after all, modding the prime generating function out by the polynomial  in
in ![F_2[x]](https://s0.wp.com/latex.php?latex=F_2%5Bx%5D&bg=ffffff&fg=000000&s=0&c=20201002) is equivalent to determining the parity of
is equivalent to determining the parity of  , and one wouldn’t expect that it should be any harder for other low-degree polynomials.
, and one wouldn’t expect that it should be any harder for other low-degree polynomials.
Comment by Ernie Croot — August 24, 2009 @ 1:27 am |
I’m boarding a plane shortly (yet again), and so can’t comment too intelligently on this very interesting approach, but I just had one quick comment: the iteration levels are basically required in order to restrict to squarefree integers (note that the parity of is essentially
is essentially  mod 4). So a toy problem would be to beat the square root barrier to compute
mod 4). So a toy problem would be to beat the square root barrier to compute 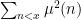 , the number of squarefrees less than x. If one can do this in some simple combinatorial manner then there is hope that the iterative process to restrict to squarefrees in general can also get past this barrier.
, the number of squarefrees less than x. If one can do this in some simple combinatorial manner then there is hope that the iterative process to restrict to squarefrees in general can also get past this barrier.
Comment by Terence Tao — August 24, 2009 @ 1:51 am |
I think I can solve the toy problem in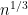 steps. The algorithm depends on access to values of the Mobius function, so we probably need to assume a factoring oracle.
steps. The algorithm depends on access to values of the Mobius function, so we probably need to assume a factoring oracle.
By Mobius inversion we have that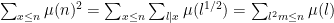 . Now we can split this last sum up as
. Now we can split this last sum up as 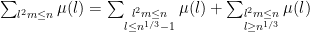 .
.
Letting![\left[ a\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+a%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002) denote the floor of a, we have that the first sum is equal to
denote the floor of a, we have that the first sum is equal to ![\sum_{l \leq n^{1/3}-1} \mu(l) \left[\frac{n}{l^2} \right]](https://s0.wp.com/latex.php?latex=%5Csum_%7Bl+%5Cleq+n%5E%7B1%2F3%7D-1%7D+%5Cmu%28l%29+%5Cleft%5B%5Cfrac%7Bn%7D%7Bl%5E2%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002) and is computable in about
and is computable in about 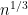 steps. Rearranging the second sum we have that
steps. Rearranging the second sum we have that 

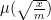 . So this is also computable in
. So this is also computable in 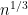 steps.
steps.
This is inspired by Roth’s proof that the largest gap between a square-free number and the next square-free number is
and the next square-free number is  .
.
Comment by Mark Lewko — August 24, 2009 @ 5:29 am |
That’s a nice problem, and probably one can do even better than Mark’s very nice approach — perhaps getting down to or better (the only reason I say this is that there are analytic estimates to count square-frees in interval widths down that low — so it seems that there are methods to sample very short intervals, analytically at least). I will think on it when I get a little free time…
or better (the only reason I say this is that there are analytic estimates to count square-frees in interval widths down that low — so it seems that there are methods to sample very short intervals, analytically at least). I will think on it when I get a little free time…
It occurs to me that one can indeed determine the parity of in time quicker than
in time quicker than  , perhaps down to
, perhaps down to  or lower: basically, from my original posting on the topic, we know that the sum of divisors up to x can be used to determine the parity of
or lower: basically, from my original posting on the topic, we know that the sum of divisors up to x can be used to determine the parity of
and we now know we can do this in time significantly below , even just using the “crude method” I discussed above — so, maybe our running time is something like
, even just using the “crude method” I discussed above — so, maybe our running time is something like  , say.
, say.
Now what we can do in this sum of pi’s above is just evaluate the last few terms trivially, by observing that
This can clearly be computed in time at worst . And what this does is it leaves us only
. And what this does is it leaves us only  terms to evaluate to compute the parity of
terms to evaluate to compute the parity of  . When all is said and done, this gives us a way to find the parity in time
. When all is said and done, this gives us a way to find the parity in time  .
.
Surely this sum over these![d \in [x^{1/3},x^{1/2}]](https://s0.wp.com/latex.php?latex=d+%5Cin+%5Bx%5E%7B1%2F3%7D%2Cx%5E%7B1%2F2%7D%5D&bg=ffffff&fg=000000&s=0&c=20201002) can be computed a lot quicker using, say, some variant of Odlyzko's method. If so, then it wouldn't surprise me if when we replace the “crude algorithm'' with something much better (to compute the sum-of-tau's in sub-exponential time, say) we end up with a way to find the parity in time
can be computed a lot quicker using, say, some variant of Odlyzko's method. If so, then it wouldn't surprise me if when we replace the “crude algorithm'' with something much better (to compute the sum-of-tau's in sub-exponential time, say) we end up with a way to find the parity in time  or better. In fact, it wouldn't surprise me if it could be done in sub-exponential time, by adding extra layers of iteration (if we can compute
or better. In fact, it wouldn't surprise me if it could be done in sub-exponential time, by adding extra layers of iteration (if we can compute  a little more quickly, then maybe we can compute weighted sums over primes — like what we had above — a little more quickly, which then means we can compute
a little more quickly, then maybe we can compute weighted sums over primes — like what we had above — a little more quickly, which then means we can compute  even quicker than before, which then means…)
even quicker than before, which then means…)
—-
Now let's say we *could* compute the sum in sub-exponential time by the
in sub-exponential time by the  method. Then perhaps a similar approach works with the
method. Then perhaps a similar approach works with the  function I wrote in a previous posting, where
function I wrote in a previous posting, where  , where
, where  is a cubic Dirichlet character mod 7. If this is so, then it seems to me that we can compute
is a cubic Dirichlet character mod 7. If this is so, then it seems to me that we can compute  mod 3 in time far below the square-root barrier as well. And a similar trick should work with other Dirichlet characters. The upshot of this is that it might be possible, after a lot of work, to compute
mod 3 in time far below the square-root barrier as well. And a similar trick should work with other Dirichlet characters. The upshot of this is that it might be possible, after a lot of work, to compute  exactly in time
exactly in time  or better!
or better!
As happened to me last week, I will have to take another week off from polymath to do my teaching and other work. See you next week…
Comment by Ernie Croot — August 24, 2009 @ 2:11 pm |
Actually, I see that there is an issue with the fact that doesn’t converge, meaning that one needs to be a little more careful in order to get a
doesn’t converge, meaning that one needs to be a little more careful in order to get a  algorithm to find the parity of
algorithm to find the parity of  . Surely it can be done somehow…
. Surely it can be done somehow…
Comment by Ernie Croot — August 24, 2009 @ 2:56 pm |
I think I can solve the toy problem in o(n^1/2) which is less than n^1/3 but doesn’t need a factoring oracle. It uses at least n^1/2 in memory so while it breaks the barrier in terms of time it pays the price in storage. It is based on the sieve of Atkins:
http://en.wikipedia.org/wiki/Sieve_of_Atkin
This computes the primes up to n in O(n/log log n)
time. The idea is as follows we first use this sieve to find the number of square free numbers up to n^1/4 and save the value for each value less than n^1/4 then for each of these numbers i we find the number of primes in the region n/p^2 is k plus a fractional value then for each prime bigger than n^1/4 we look at those primes for which n/p^2 =k rounded down has the same value then we used the data from the algorithm for lower values to see how man of the values one through k are square free then we have an accurate count of the number of numbers removed by the primes and the whole process should be o(n^1/2) although the memory used is at least O(n^1/2).
Comment by Kristal Cantwell — August 26, 2009 @ 9:28 pm |
Since the Odlyzko (or Meissel-Lehmer) method compute exactly, we can use it to compute the
exactly, we can use it to compute the  -th prime exactly via a binary search in around
-th prime exactly via a binary search in around  steps.
steps.
This is stronger than we need, since we only aim to find some -digit prime. One strategy for trading some of this precision for speed is to try to compute
-digit prime. One strategy for trading some of this precision for speed is to try to compute  , where
, where  is about
is about  using these methods. With a binary search, and the RH prime gap result, we just need to get this computation below
using these methods. With a binary search, and the RH prime gap result, we just need to get this computation below  steps. I spent a while trying to modify the Meissel-Lehmer method to do this, however I haven’t fully figured out how to make this work. Maybe someone else has some thoughts about this.
steps. I spent a while trying to modify the Meissel-Lehmer method to do this, however I haven’t fully figured out how to make this work. Maybe someone else has some thoughts about this.
Let me say a little bit about how this strategy might work. I’ll use the notation from the exposition of the Meissel-Lehmer method in the book “Algorithmic Number Theory” by Eric Bach and Jeffery Shallit.
Let be the number of primes in the interval
be the number of primes in the interval ![[x,x+h]](https://s0.wp.com/latex.php?latex=%5Bx%2Cx%2Bh%5D&bg=ffffff&fg=000000&s=0&c=20201002) and let
and let 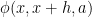 denote the number of integers in
denote the number of integers in ![[x,x+h]](https://s0.wp.com/latex.php?latex=%5Bx%2Cx%2Bh%5D&bg=ffffff&fg=000000&s=0&c=20201002) such that all of the prime factors are greater than the a-th prime,
such that all of the prime factors are greater than the a-th prime, 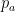 . Also let
. Also let 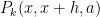 denote the number of integers in the range with exactly k prime divisors, all of which are greater than
denote the number of integers in the range with exactly k prime divisors, all of which are greater than 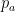 . Clearly
. Clearly  (here we define
(here we define 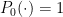 ). Now let
). Now let  . This gives us that
. This gives us that  . Rearranging this gives us that
. Rearranging this gives us that 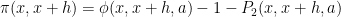 .
.
Let us first deal with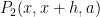 . This can be expanded as
. This can be expanded as 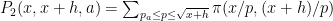 . Of course,
. Of course,  . So the largest value of
. So the largest value of  we will need to evaluate will be around
we will need to evaluate will be around  . As long as
. As long as  is of lower order than
is of lower order than  (such as
(such as  ) then the largest value of
) then the largest value of  we need to evaluate is around
we need to evaluate is around  . Using the Meissel-Lehmer method (without any modifications) we can do this is
. Using the Meissel-Lehmer method (without any modifications) we can do this is 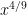 steps (using Odlyzko’s method, we could get this down to
steps (using Odlyzko’s method, we could get this down to  steps). I’d like to say that it shouldn’t be much more expensive than this to compute all of the values of
steps). I’d like to say that it shouldn’t be much more expensive than this to compute all of the values of  we need for
we need for  , since we should be able to cache a lot of steps, but I’m unsure about this.
, since we should be able to cache a lot of steps, but I’m unsure about this.
We are left to compute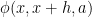 . We can recursively compute this using the identity
. We can recursively compute this using the identity  . Now (on RH) we assume that
. Now (on RH) we assume that 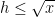 . To evaluate
. To evaluate 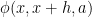 recursively, we can form a tree with a top node of
recursively, we can form a tree with a top node of 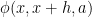 and two branches leading from this node to
and two branches leading from this node to  and
and  . From each of these nodes we form two more branches, again using the identity, until a stopping condition is met. There are two situations in which the evaluation of
. From each of these nodes we form two more branches, again using the identity, until a stopping condition is met. There are two situations in which the evaluation of  is easy. First if
is easy. First if  then
then  is the number of odd elements in the interval
is the number of odd elements in the interval ![[x,y]](https://s0.wp.com/latex.php?latex=%5Bx%2Cy%5D&bg=ffffff&fg=000000&s=0&c=20201002) . Also if
. Also if  then
then  is easy to compute. We could keep expanding our tree until one of these two conditions are met, but this isn’t efficient. Notice that every node of the tree is of the form
is easy to compute. We could keep expanding our tree until one of these two conditions are met, but this isn’t efficient. Notice that every node of the tree is of the form 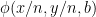 where
where ![[x,y]](https://s0.wp.com/latex.php?latex=%5Bx%2Cy%5D&bg=ffffff&fg=000000&s=0&c=20201002) was our initial interval. Moreover, an expression of this form can occur on at most 1 node of the tree.
was our initial interval. Moreover, an expression of this form can occur on at most 1 node of the tree.
Our stopping condition will be either of the following:
(i) b=1 and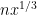 . (these are “special leaves”)
. (these are “special leaves”)
Since a distinct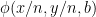 can occur on at most one node, there are at most
can occur on at most one node, there are at most  ordinary leaves. Moreover, we have an exact expression to compute these, so the sum over these can be done in about
ordinary leaves. Moreover, we have an exact expression to compute these, so the sum over these can be done in about  steps.
steps.
The special leaves are the problem however. The n-value in the parent of a special leave must satisfy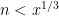 , and
, and  (by construction), which implies that there are less than
(by construction), which implies that there are less than  special leaves. Unfortunetly this isn't good enough, since any computation that looks at all of them won't get below
special leaves. Unfortunetly this isn't good enough, since any computation that looks at all of them won't get below  steps.
steps.
Comment by Mark Lewko — August 24, 2009 @ 2:02 am |
WordPress truncated the stopping condition, it should have been:
(i) b=1 and (these are “ordinary leaves”)
(these are “ordinary leaves”) . (these are “special leaves”)
. (these are “special leaves”)
(ii)
Comment by Mark Lewko — August 24, 2009 @ 5:47 am |
Wow – amazing synchronicity. I stumbled across this page trying to find if anyone, anywhere, knew of faster ways to count sums of divisor functions, and it turns out that you folks look like you’re not only talking about that, but for very similar reasons to me.
A few years ago, I wrote some code in C to calculate the count of primes < n by calculating the various sum of divisor functions and then applying Linnik's identity. I tried to do everything I could to speed it up, but ultimately I never could get it fast enough to be competitive. I think the current version runs in something like O(n^4/5) time (at least from eyeballing it) and O(epsilon) space, but because the various loops for the sums of divisor functions are particularly sped up by aggressive use of wheels, I think its constant time factors are pretty good – or at least for an algorithm with O(epsilon) for memory. It calculates 10^12 in about a second on my reasonably decent laptop with a wheel culling out primes up to 19.
The code is here
http://www.icecreambreakfast.com/math/mckenzie_math.pdf (the code is at the bottom of this pdf, along with descriptions of what I'm doing above it)
if anyone wants to look over it or play with it. I keep trying to find some way to rearrange things in the algorithm to find some clever way to cache… something… to massively speed things up, but so far I've had no real luck. I've tried a lot of things, but I clearly haven't stumbled on the right idea yet. I could list some of those if anyone is interested.
At any rate, if any of you feel like taking a look at the code and seeing if you have any brilliant ideas, I would be overjoyed. While I wasn't looking, this whole topic (counting sums of divisors quickly) has turned into my Ahab-style White Whale.
Comment by Nathan McKenzie — August 27, 2009 @ 10:02 am |
[…] previous research thread for the “finding primes” project is now getting quite full, so I am opening up a fresh […]
Pingback by (Research Thread IV) Determinstic way to find primes « The polymath blog — August 28, 2009 @ 1:44 am |
What about the misspelling in the title?
[Corrected, thanks – T.]
Comment by Ruth — December 19, 2018 @ 6:11 pm |