I’ve written up a draft version of a short paper giving the results we already have in the finding primes project. The source files for the paper can be found here.
The paper is focused on what I think is our best partial result, namely that the prime counting polynomial 

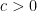

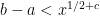
![[a,b]](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D&bg=ffffff&fg=000000&s=0&c=20201002)
I’d be interested in hearing the other participants opinions about where to go next. Ernie has suggested that experimenting with variants of the algorithm could make a good REU project, in which case we might try to wrap up the project with the partial result and pass the torch on.

Wow! I glanced at it earlier today — it looks very efficiently written. I will try to read it over tomorrow very carefully for errors.
I think what’s in the paper is good enough… and it’s best to wrap it up at this point, but that’s just by 2 cents.
Today (and last week) I discussed several directions in which to take the project with two REU students… if you think it is a good idea, perhaps you might mention a subset of these in the paper:
1. By doing a linear approximation to n/x we get speedups in lattice-point counting… but you can try to do higher-order polynomial approximations instead. I believe this leads to counting lattice points below a polynomial curve. If this can be done efficiently — as efficiently in the linear case — then it will lead to a vast speedup in the parity-of-pi algorithm (though not for the polynomial analoue). Just today we worked on the quadratic case of this, and came up with several ideas (a promising approach we came up with was to try to tile the polynomial region by affine [actually, rotated and translated] copies of certain polynomial sub-regions).
2. I still think the idea of computing quickly, where
quickly, where  is a polynomial, is a nice problem. It turns out not to be so straightforward (though I don’t think it will prove to be THAT difficult in the end)… which makes it all the more intriguing.
is a polynomial, is a nice problem. It turns out not to be so straightforward (though I don’t think it will prove to be THAT difficult in the end)… which makes it all the more intriguing.
3. Besides FFTs, there might still be a way to get FFT-level performance using “matrix arithmetic”… which would be good, because these matrix approaches work over any ring. I suggested that maybe the sort of structure one should try is higher-dimensional matrices. Are there Strassen-type algorithms that work for higher-dimensional matrices, that give better and better speedups the more dimensions one uses? I have not been able to track down the appropriate literature on higher-dimensional matrices, though I know it exists. I’m guessing there’s a way to rephrase this strategy somehow in terms of tensors or something. It seems there are many possible generalizations (from the 2D case) that one try can here. One thought for the 3D case was to think of “matrix multiplication” as involving a “trinary form”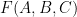 , where
, where 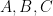 are 3D matrices; and, in general, the “multiplication” of
are 3D matrices; and, in general, the “multiplication” of  -dimensional matrices should involve
-dimensional matrices should involve  -ary forms.
-ary forms.
Anyways, if no “higher dimensional” analogue of Strassen exists, then that alone would make a nice project to explore (and maybe it would have lots of applications! — I could imagine it would, especially if you get better and better results the more dimensions you use).
These are just a few of the things we have been thinking about…
Comment by Ernie Croot — June 30, 2010 @ 4:26 am |
These are great new directions to explore, but given that others will be exploring them I am a little hesitant to detail them too much in this current paper in order to give the next group of people a bit more space. But perhaps we can hint at such developments. Incidentally, you are of course free to send me any specific text you would like in the paper (either here, by email, or via Subversion).
Comment by Terence Tao — June 30, 2010 @ 6:20 pm |
An orthogonal comment, but I wanted to say that I was very pleased to see that a paper had resulted from this discussion. It’s still far too early to say what a “typical” outcome is for a Polymath project, but I now don’t think it’s too early to say that if the discussion gets going then it will almost certainly lead to something publishable. The experience here, and also with the Erdős discrepancy project, has been that even if the “main” problem is not solved, the process almost inevitably leads to new insights and a deeper understanding of that problem, to the point where they are worth publishing. (If EDP is not eventually crowned with success, then there will certainly be a paper or two’s worth of material to be extracted from the discussion.)
Comment by gowers — June 30, 2010 @ 10:17 am |
Well, one of the useful consequences of a Polymath project is that it reveals to some extent what actual mathematical research is like – and in particular, that partial success is in fact far more common than total success once one gets to really non-trivial problems (i.e. ones that are more than just applying a known method to a problem that is well within range of that method). This fact is often obscured by selection bias in the traditional research paradigm…
Comment by Terence Tao — June 30, 2010 @ 6:22 pm |
Another comment. I see that the author of this paper is D.H.J. Polymath, which doesn’t make all that much sense. I had originally imagined that all polymath papers would simply be by Polymath, but Ryan O’Donnell came up with the DHJ idea for the DHJ papers. Since nothing has yet been published (though there have by now been some references to the DHJ papers in other papers) it’s perhaps not too late to decide what convention we want to adopt. The three I can think of are to drop the DHJ on the DHJ papers and do without initials from now on, to keep DHJ for all papers (which is a bit strange, but could be thought of as marking the fact that the DHJ papers were the first), or to have different initials for each project (so this one might be e.g. FPD, and the discrepancy one might be EDP, or just ED).
Comment by gowers — June 30, 2010 @ 10:45 am |
Well, on some level all pseudonyms are equally artificial. I have a slight preference for using a unified pseudonym so that Polymath can behave (for the purposes of citation indices etc.) like a single prolific author rather than a whole family of one-hit authors, and DHJ is as good a choice as any other. I also have a slight fear that if we make a cleverly contrived nom de plume for each paper, it may make the series look unnecessarily artificial or “gimmicky” in nature. (Imagine for instance if Bourbaki used the name of a different French general for each branch of mathematics, with some clever association that “explained” the choice of each general for each branch; while entertaining, this would no doubt distract from the primary purpose of their exposition.)
Comment by Terence Tao — June 30, 2010 @ 6:32 pm |
I share your preference for a unified pseudonym, partly because it means that Polymath’s papers will straightforwardly appear in the same place on MathSciNet (without the need to remove the initials), the arXiv etc.
Comment by gowers — July 1, 2010 @ 8:15 am |
I emailed Ryan and it turns out that he had originally imagined different initials for each project, to indicate that the sets of authors were different. But he points out that that has already failed to happen with the two DHJ papers (which, although both about aspects of DHJ, were by different sets of authors), and he’s happy to go with the idea of having DHJ Polymath be the author for all polymath papers and thinking of the initials as a reminder of the first project.
Comment by gowers — July 1, 2010 @ 1:18 pm |
I think one pseudonym would be better than many different ones that differ by a couple of letters.
Comment by kristalcantwell — July 4, 2010 @ 8:33 pm |
Ok, I’ve read over the draft. It is VERY nicely written! I have a few comments, however:
1. In the time complexities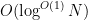 , we don’t really need that extra big-O outside — we could just write
, we don’t really need that extra big-O outside — we could just write 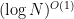 , for instance. In the
, for instance. In the  , on the other hand, keeping the big-O is fine, so as to emphasize that it gives an UPPER BOUND.
, on the other hand, keeping the big-O is fine, so as to emphasize that it gives an UPPER BOUND.
2. On page 2, I would put a space between “Heath-Brown” and [6]. Also, at the bottom of page 2, there is an extra `.’.
3. On page 3, you write , but the
, but the 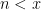 should be
should be  . In the sentence “Since, by as mentioned earlier…'', delete `by'.
. In the sentence “Since, by as mentioned earlier…'', delete `by'.
4. On page 4, in the parenthetical comment “addition, subtraction…''. You might emphasize that we add `division', which I don't think is standard in the definition of “arithmetic circuit complexity''. In finite rings, perhaps it is ok to include it, since one can use the power map to produce multiplicative inverses.
Also, you write , and then forget to put the matching
, and then forget to put the matching  ; and, the
; and, the 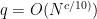 has an extra
has an extra  .
.
5. On page 5, you say “…distinct prime powers of ''. It should be “… distinct prime power divisors of
''. It should be “… distinct prime power divisors of  .''
.''
6. Also on page 5, you write , when in fact it should just be `
, when in fact it should just be ` ', as it is an identity, not a definition (or assignment).
', as it is an identity, not a definition (or assignment).
7. On page 8, I think you mean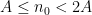 , not
, not  . Also on page 8, you say as
. Also on page 8, you say as  runs from
runs from  to
to  , when you mean
, when you mean  to
to 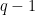 . Also, you say here “
. Also, you say here “ th root of unity'', maybe you should add the word “additive'' or reword it altogether.
th root of unity'', maybe you should add the word “additive'' or reword it altogether.
8. On page 11, under “Possible extensions'', first sentence: I think you want to take the degree of to be
to be  or something, and then have the time be
or something, and then have the time be  .
.
Comment by Ernie Croot — July 1, 2010 @ 8:14 pm |
Thanks very much Ernie! I have incorporated the comments and some further corrections and the new draft is now available at
Click to access polymath.pdf
I guess we should wait to hear from Harald and any other participants before deciding what next to do. I think the paper is close to being ready to be uploaded to the arXiv, and perhaps also submitted to some journal that can handle computational number theory (e.g Mathematics of Computation, which has Igor Shparlinski as one of the editors).
Comment by Terence Tao — July 1, 2010 @ 9:42 pm |
I was stuck in airports for a couple of days, and now I have some urgent paperwork to fill out – I will be back to this shortly.
Comment by Harald Helfgott — July 3, 2010 @ 11:15 pm |
I was thinking about the writeup, and in particular that you compute instead of
instead of 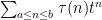 as I had suggested… and it made me wonder what I was missing. Then, I looked at the draft again, and I think I have found a error in your writeup: At the bottom of page 10, and top of page 11, where you use the geometric series formula, you divide by
as I had suggested… and it made me wonder what I was missing. Then, I looked at the draft again, and I think I have found a error in your writeup: At the bottom of page 10, and top of page 11, where you use the geometric series formula, you divide by 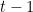 , not
, not  .
.
Maybe I’m just misreading this, though…
Comment by Ernie Croot — July 2, 2010 @ 3:38 pm |
Oops, that was a silly mistake on my part – I thought I found a neat simplification and strengthening of your argument but that turns out not to work. (I had the vague analogy with Stokes’ theorem and thought every interior sum could be converted into a boundary sum, but now I see why that doesn’t work…)
Comment by Terence Tao — July 2, 2010 @ 4:45 pm |
Here is a repaired version:
Click to access polymath1.pdf
Comment by Terence Tao — July 2, 2010 @ 5:12 pm |
[…] is now a thread about the paper mentioned […]
Pingback by Polymath4 « Euclidean Ramsey Theory — July 4, 2010 @ 5:47 pm |
I made a very short list of tiny typos – and now I cannot find it. At any rate, I rather like the paper right now – in particular the third section.
Comment by Harald Helfgott — July 6, 2010 @ 5:42 pm |
This is very nice. I wonder if there were further insights/problems from the many polymath4 research threads which we should either mention in the paper or perhaps in a post. (Of course, one can simply look at the threads themselves.)
Comment by Gil Kalai — July 9, 2010 @ 4:54 pm |
I just wanted to write that it turns out that there is a simple algorithm to do multipoint polynomial evaluation in any ring very efficiently (one of my REU students looked it up); so the part of the paper where we use the fast matrix multiplication algorithm can be replaced with a literature reference (I asked my student to email it to me — when he does, I will post it here). Basically, it works as follows: Let’s suppose we can multiply together two polynomials of degrees and
and  , respectively, in time roughly
, respectively, in time roughly 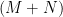 , times some logs, in some ring
, times some logs, in some ring  . It is easy to see then that we can compute one polynomial mod another just about as fast (times some small constant). Now suppose we have a polynomial
. It is easy to see then that we can compute one polynomial mod another just about as fast (times some small constant). Now suppose we have a polynomial  of degree
of degree  and some points
and some points  , and we want to evaluate
, and we want to evaluate  . How do we do it quickly? Well, what we can do is define the polynomials
. How do we do it quickly? Well, what we can do is define the polynomials
and
and then compute
and
where the degrees of and
and  are both smaller than
are both smaller than 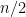 . Now, it is easy to see that
. Now, it is easy to see that
So, we have a “divide and conquer” strategy for doing multipoint evaluation. One detail remains: How do we compute those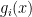 polynomials quickly as we iterate? Well, what you can do is build up a tree of polynomial products, starting at the leaves. First, you compute the
polynomials quickly as we iterate? Well, what you can do is build up a tree of polynomial products, starting at the leaves. First, you compute the 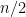 polynomials
polynomials
and then you multiply consecutive pairs of *these* together to give the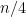 polynomials
polynomials
and eventually, you get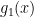 and
and 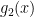 … and in fact all the other polynomials you will need for your divide-and-conquer.
… and in fact all the other polynomials you will need for your divide-and-conquer.
…
Now, to multiply together two polynomials in time about (times some logs) as discussed above, it turns out that there is an algorithm due to Strassen to handle this, which doesn’t use FFTs (it just uses some Karatsuba-type identities); even so, perhaps we can just use the standard FFT algorithm in an obvious way, thinking of the polynomials first as belonging to
(times some logs) as discussed above, it turns out that there is an algorithm due to Strassen to handle this, which doesn’t use FFTs (it just uses some Karatsuba-type identities); even so, perhaps we can just use the standard FFT algorithm in an obvious way, thinking of the polynomials first as belonging to ![Z[x]](https://s0.wp.com/latex.php?latex=Z%5Bx%5D&bg=ffffff&fg=000000&s=0&c=20201002) or perhaps
or perhaps ![Z[x,y]](https://s0.wp.com/latex.php?latex=Z%5Bx%2Cy%5D&bg=ffffff&fg=000000&s=0&c=20201002) , and then modding out by
, and then modding out by  later on.
later on.
Comment by Ernie Croot — August 4, 2010 @ 7:56 pm |
Ok, here is the reference in the literature to the fast multi-point algorithm:
A. Borodin and R. Moenk, “Fast Modular Transforms”, Jour. of Comp. and System Sciences, 8 (1974), 366-386.
And, in case it matters later on in some way, the two students continuing Polymath4 with me are: David Hollis and David Lowry.
Comment by Ernie Croot — August 13, 2010 @ 12:44 am |
Dear Ernie, sorry for not getting back to you earlier, I’ve been unusually distracted in the last two weeks.
I uploaded a new version mentioning multipoint evaluation and possible future work (see final section) at
Click to access polymath.pdf
I am unsure about the wording, so please check.
I think we should be ready to submit the paper to journal as soon as there is consensus to do so. I was thinking of submitting to Mathematics of Computation, if that is OK with everyone…
Comment by Terence Tao — August 20, 2010 @ 7:52 pm |
[Dear Ernie, sorry for not getting back to you earlier, I’ve been unusually distracted in the last two weeks.]
I totally understand, especially given the ICM conference and all.
[I am unsure about the wording, so please check.]
The wording looks fine to me; and I’m sure David and David would appreciate seeing that they are mentioned (and perhaps when they go to apply for grad school… etc.). It’s looking like we might be able to prove a fast algorithm for , as hoped; I'll know for sure in another two weeks or so (after I return from India, and get to meet with them again).
, as hoped; I'll know for sure in another two weeks or so (after I return from India, and get to meet with them again).
…
I see that you list the Borodin and Moenk paper, but didn't see that you replaced the use of matrices in the proof of Lemma 3.1 with a reference to it. Now that I think about it, I think I like including the matrix argument instead of just doing a citation. The fact is that everyone is familiar with Strassen's matrix algorithm, while few people know the argument in B-M; and so, the present argument in Lemma 3.1 is more self-contained (given the Strassen matrix alg.), and would be but one or two lines shorter anyways, if we just used the result in B-M (instead of matrices).
…
I would like to look over the paper again carefully before we submit it; but that will be a week or two from now, as I will be leaving for India tomorrow.
Comment by Ernie Croot — August 26, 2010 @ 4:28 am |
OK. I was not sure exactly how to cite the BM paper in the proof of Lemma 3.1, so if you have some suggested wording, I can splice it in. Enjoy India; I didn’t go to the ICM this time around, but I did very much enjoy my last trip to that country…
Comment by Terence Tao — August 26, 2010 @ 4:34 am |
[…] Polymath4 By kristalcantwell There is a new draft for the paper for Polymath4. It is here. It may be submitted to Mathematics of Computation. For more information see this post. […]
Pingback by Polymath4 « Euclidean Ramsey Theory — August 20, 2010 @ 8:42 pm |
Hello.
I’m sorry for this off topic (first) post. I was just reading through the wiki page for this project, and noticed that the solution to a toy problem hinged on a conjecture about Sylvester’s sequence. I’m fairly sure that I’ve proved it quite simply, but I may be ignoring some complication. I put my proof up on the wiki page.
Again, apologies for the off topic post (and if there’s somewhere better for me to out this kind of stuff, please let me know).
Thanks
-Zomega
Comment by Zomega — August 23, 2010 @ 8:42 pm |
Dear Zomega,
Thanks for your edit. Unfortunately, there is more to a natural number n being squarefree than simply not being a square; one must also show that n is not divisible by any square larger than 1, see http://en.wikipedia.org/wiki/Square-free_integer .
Comment by Terence Tao — August 23, 2010 @ 8:45 pm |
I realize that now. My apologies for making such a gigantic error. I’ll check my work more carefully in the future.
-Zomega
Comment by Zomega — August 24, 2010 @ 12:57 am |
Sorry for the long delay in writing about the last draft… I think it is pretty much ready to go; however, I found a few more small typos and things:
1. Page 7, there are two of’s.
2. Page 7, “coefficients O(x)” –> “coefficients of size O(x)”.
3. page 7, “If we restrict to the range… the second term”, I think should be “third term”. And “third term” should be “fourth term”.
4. Page 8, “It suffices to show… in time” –> “… that we can compute in time.”
5. Pag 10, near the bottom: You write that , but all we have is
, but all we have is  ; however, since
; however, since  , where
, where  are all “small”, this isn’t much of an issue.
are all “small”, this isn’t much of an issue.
Comment by Ernie Croot — September 20, 2010 @ 3:38 pm |
Thanks Ernie! I’ll submit it now to the arXiv and to Math. Comp. Always a good feeling when a project has reached completion…
Comment by Terence Tao — September 20, 2010 @ 9:18 pm |
The paper is now on the arXiv at
http://arxiv.org/abs/1009.3956
and submitted to Mathematics of Computation.
Comment by Terence Tao — September 22, 2010 @ 3:21 am |
I wanted to the answer to a slightly different but simple question:
Is there an algorithm which on input , finds a prime larger than
, finds a prime larger than  , with running time bounded by a polynomial in
, with running time bounded by a polynomial in  ?
?
Comment by Girish Varma — November 18, 2010 @ 4:39 pm |
Hello. Is this wonderfully number theoretic thread (and the original problem) still open? Just wondering.
Comment by Anonymous — December 23, 2011 @ 8:37 am |
Hello, I was reading http://arxiv.org/pdf/1009.3956v3.pdf and have some comments.
One of your key identities EQ2.1
2^w(n)= sum(d^2|n)of mobius(d) * tau(n/d^2)
can be generalized. Let m be any integer with m>=0.
2^(m*w(n)) =
m-fold-sum( d1^2|n, d2^2|n, …, dm^2|n )of
mobius(d1)*mobius(d2)*…*mobius(dm) * tau(n/d1^2) * tau(n/d2^2) *…* tau(n/dm^2).
PROOF SKETCH:
It is easy to see this identity is valid in the following easy cases:
(i) m=0 when it is just 1=1, we agree 0-fold-sum is 1.
(ii) m=1 when it is your old identity.
(iii) n=squarefree when only summand comes from d1=d2=…=dm=1.
(iv) n=p^k=prime power when all dj=1 or p:
If k=0 we get n=1 and 2^(m*w(1))=2^0=1=1.
If k=1 we get 2^m=2^m.
If k>=2 we get 2^m=([k+1]-[k-1])^m=2^m.
Now use coprime-multiplicativity to see the easy cases imply validity for all cases.
QED.
This would enable you to count primes in [a,b] not mod 2, but in fact mod 2^m,
for any desired m>=0. If m>log2(b-a+1) this would count the primes, full stop.
Can this be made efficient? I have not tried to figure that out.
Warren D Smith, warren.wds AT gmail.com
Comment by Warren D Smith — March 23, 2012 @ 11:58 pm |
Such an insightful read! Your blog consistently delivers valuable content that keeps me engaged and enlightened. Thank you for sharing your knowledge and expertise with us.
Best Financial Planning Services
Comment by Anonymous — May 29, 2024 @ 8:03 am |