Michael Nielsen has collected a number of possible logos for the polymath wiki and is asking for discussion on them.
April 28, 2011
March 9, 2011
Polymath discussion at IAS
In October 2010 there was a discussion about polymath projects at an event organized by the I.A.S in NYC. Tim Gowers described the endeavor and some prospects, and hopes, and Peter Sarnak responded with some concerns. An interesting discussion followed. Some of the discussion is described in the IAS Institute Letter for fall 2010 .
February 14, 2011
Polymath4: Referee report obtained
An update on the status of the Polymath4 paper on finding primes. I’ve received a referee report from Mathematics of Computation on the submission, which can be found here. The referee liked the result but wanted a fair number of expository changes before he or she was willing to recommend acceptance, so the editor has asked for a revision. I will be happy to make the relevant changes, but if there are any other changes that other participants would like to make, now would be a good time to suggest them. (The most recent version of the paper can be found at the Subversion repository or at this link; see also the arXiv version.)
One change requested is to add a list of participants to the project. In analogy with what we did for Polymath1, I therefore started a “signup sheet” on the wiki at
http://michaelnielsen.org/polymath1/index.php?title=Polymath4_grant_acknowledgments
for people to self-report their participation, contact information, and grant information for the project. There is the usual problem of trying to decide who is a “main participant” of the project, and who is a “contributor” (though I think I can safely add Ernie, Harald, and myself as participants); as with Polymath1, I will leave it to each of you to self-report what level of participation you feel is appropriate.
February 13, 2011
Can Bourgain’s argument be usefully modified?
I’ve been feeling slightly guilty over the last few days because I’ve been thinking privately about the problem of improving the Roth bounds. However, the kinds of things I was thinking about felt somehow easier to do on my own, and my plan was always to go public if I had any idea that was a recognisable advance on the problem.
I’m sorry to say that the converse is false: I am going public, but as far as I know I haven’t made any sort of advance. Nevertheless, my musings have thrown up some questions that other people might like to comment on or think about.
Two more quick remarks before I get on to any mathematics. The first is that I still think it is important to have as complete a record of our thought processes as is reasonable. So I typed mine into a file as I was having them, and the file is available here to anyone who might be interested. The rest of this post will be a sort of digest of the contents of that file. The second remark is that I am writing this as a post rather than a comment because it feels to me as though it is the beginning of a strand of discussion rather than the continuation of one, though it grows out of some of the comments made on the last post. Note that since we are operating on the Polymath blog, anybody else is free to write a post too (if you are likely to be one of the main contributors, haven’t got moderator status and want it, get in touch and I can organize it).
The starting point for this line of thought is that the main difficulty we face seems to be that Bourgain’s Bohr-sets approach to Roth is in a sense the obvious translation of Meshulam’s argument, but because we have to make a width sacrifice at each iteration it gives a 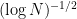

February 5, 2011
Polymath6: improving the bounds for Roth’s theorem
For the time being this is an almost empty post, the main purpose of which is to provide a space for mathematical comments connected with the project of assessing whether it is possible to use the recent ideas of Sanders and of Bateman and Katz to break the 
Added later. Tom Sanders made the following remarks as a comment. It seems to me to make more sense to have them as a post, since they are a good starting point for a discussion. So I have taken the liberty of upgrading the comment. Thus, the remainder of this post is written by Tom.
This will hopefully be an informal post on one aspect of what we might need to do to translate the Bateman-Katz work into the 
One of the first steps in the Bateman-Katz argument is to note that if 

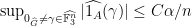
They use this to develop structural information about the large spectrum, 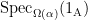


September 30, 2010
Polymath3 (polynomial Hirsch conjecture) now officially open
After some discussion and a lengthy hiatus, the Polymath3 project (on attacking the polynomial Hirsch conjecture via combinatorial means) has officially started with a new research thread on Gil Kalai’s blog (which, for now, can also double as the discussion thread, given that the activity level is still quite low), and a Polymath wiki page.
July 8, 2010
Minipolymath2 project: IMO 2010 Q5
This post marks the official opening of the mini-polymath2 project to solve a problem from the 2010 IMO. I have selected the fifth question (which appears to be slightly more challenging than the sixth, for a change) as the problem to focus on:
Problem. In each of six boxesthere is initially one coin. There are two types of operation allowed:
- Type 1: Choose a nonempty box
with
. Remove one coin from
.
- Type 2: Choose a nonempty box
with
. Remove one coin from
and
.
Determine whether there is a finite sequence of such operations that results in boxesbeing empty and box
containing exactly
coins. (Note that
.)
The comments to this post shall serve as the research thread for the project, in which participants are encouraged to post their thoughts and comments on the problem, even if (or especially if) they are only partially conclusive. Participants are also encouraged to visit the discussion thread for this project, and also to visit and work on the wiki page to organise the progress made so far.
This project will follow the general polymath rules. In particular:
- All are welcome. Everyone (regardless of mathematical level) is welcome to participate. Even very simple or “obvious” comments, or comments that help clarify a previous observation, can be valuable.
- No spoilers! It is inevitable that solutions to this problem will become available on the internet very shortly. If you are intending to participate in this project, I ask that you refrain from looking up these solutions, and that those of you have already seen a solution to the problem refrain from giving out spoilers, until at least one solution has already been obtained organically from the project.
- Not a race. This is not intended to be a race between individuals; the purpose of the polymath experiment is to solve problems collaboratively rather than individually, by proceeding via a multitude of small observations and steps shared between all participants. If you find yourself tempted to work out the entire problem by yourself in isolation, I would request that you refrain from revealing any solutions you obtain in this manner until after the main project has reached at least one solution on its own.
- Update the wiki. Once the number of comments here becomes too large to easily digest at once, participants are encouraged to work on the wiki page to summarise the progress made so far, to help others get up to speed on the status of the project.
- Metacomments go in the discussion thread. Any non-research discussions regarding the project (e.g. organisational suggestions, or commentary on the current progress) should be made at the discussion thread.
- Be polite and constructive, and make your comments as easy to understand as possible. Bear in mind that the mathematical level and background of participants may vary widely.
Have fun!
June 29, 2010
Draft version of polymath4 paper
I’ve written up a draft version of a short paper giving the results we already have in the finding primes project. The source files for the paper can be found here.
The paper is focused on what I think is our best partial result, namely that the prime counting polynomial 

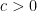

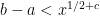
![[a,b]](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D&bg=ffffff&fg=000000&s=0&c=20201002)
I’d be interested in hearing the other participants opinions about where to go next. Ernie has suggested that experimenting with variants of the algorithm could make a good REU project, in which case we might try to wrap up the project with the partial result and pass the torch on.
June 12, 2010
Mini-polymath proposal: IMO 2010 Q6
I am proposing the sixth question for the 2010 International Mathematical Olympiad (traditionally, the trickiest of the six problems) as a mini-polymath project for next month. Details and discussions are in this post on my other blog.
[Update, June 27: the project is scheduled to start on Thursday, July 8 16:00 UTC.]
